

En Resumen
- Multiverse Computing recaudó $215 millones en Serie B tras afirmar que su tecnología CompactifAI puede reducir modelos de IA en 95% sin comprometer rendimiento
- La startup española demostró que logró comprimir Llama-2 7B reduciendo parámetros en 70% y acelerando inferencia 25% con solo 2-3% de pérdida en precisión
- La compañía señaló que utiliza redes tensoriales inspiradas en física cuántica para preservar correlaciones significativas mientras descarta patrones redundantes
Una startup de inteligencia artificial española acaba de convencer a los inversores de entregar $215 millones basándose en una afirmación audaz: pueden reducir los Large Language Models (LLMs) en un 95% sin comprometer su rendimiento.
La innovación de Multiverse Computing se basa en su tecnología CompactifAI, un método de compresión que toma prestados conceptos matemáticos de la física cuántica para reducir los modelos de IA al tamaño de un smartphone.
La empresa de San Sebastián dice que su modelo comprimido Llama-2 7B funciona 25% más rápido en inferencia mientras utiliza 70% menos parámetros, con una precisión que cae solo 2-3%.
Si se valida a gran escala, esto podría abordar el problema del tamaño de elefante de la IA: modelos tan masivos que requieren centros de datos especializados solo para operar.
"Por primera vez en la historia, somos capaces de perfilar el funcionamiento interno de una red neuronal para eliminar miles de millones de correlaciones espurias y verdaderamente optimizar todo tipo de modelos de IA", dijo Román Orús, director científico de Multiverse, en una publicación de blog el jueves.
Bullhound Capital lideró la ronda Serie B de $215 millones con respaldo de HP Tech Ventures y Toshiba.
La Física Detrás de la Compresión
Aplicar conceptos inspirados en la cuántica para abordar uno de los problemas más apremiantes de la IA suena improbable, pero si la investigación se sostiene, podría ser real.
A diferencia de la compresión tradicional que simplemente corta neuronas o reduce la precisión numérica, CompactifAI utiliza redes tensoriales: estructuras matemáticas que los físicos desarrollaron para rastrear interacciones de partículas sin ahogarse en datos.
El proceso funciona como un origami para modelos de IA: las matrices de peso se pliegan en estructuras más pequeñas e interconectadas llamadas Operadores de Producto Matricial.
En lugar de almacenar cada conexión entre neuronas, el sistema preserva solo correlaciones significativas mientras descarta patrones redundantes, como información o relaciones que se repiten una y otra vez.
Multiverse descubrió que los modelos de IA no son uniformemente comprimibles. Las capas tempranas resultan frágiles, mientras que las capas más profundas —recientemente demostradas como menos críticas para el rendimiento— pueden soportar compresión agresiva.
Este enfoque selectivo les permite lograr reducciones dramáticas de tamaño donde otros métodos fallan.
Después de la compresión, los modelos se someten a una breve "curación": reentrenamiento que toma menos de una época gracias al recuento reducido de parámetros. La empresa afirma que este proceso de restauración funciona 50% más rápido que entrenar modelos originales debido a las cargas reducidas de transferencia GPU-CPU.
En resumen, según las propias ofertas de la empresa, empiezas con un modelo, ejecutas la magia Compactify, y terminas con una versión comprimida que tiene menos del 50% de sus parámetros, puede funcionar al doble de velocidad de inferencia, cuesta mucho menos, y es tan capaz como el original.
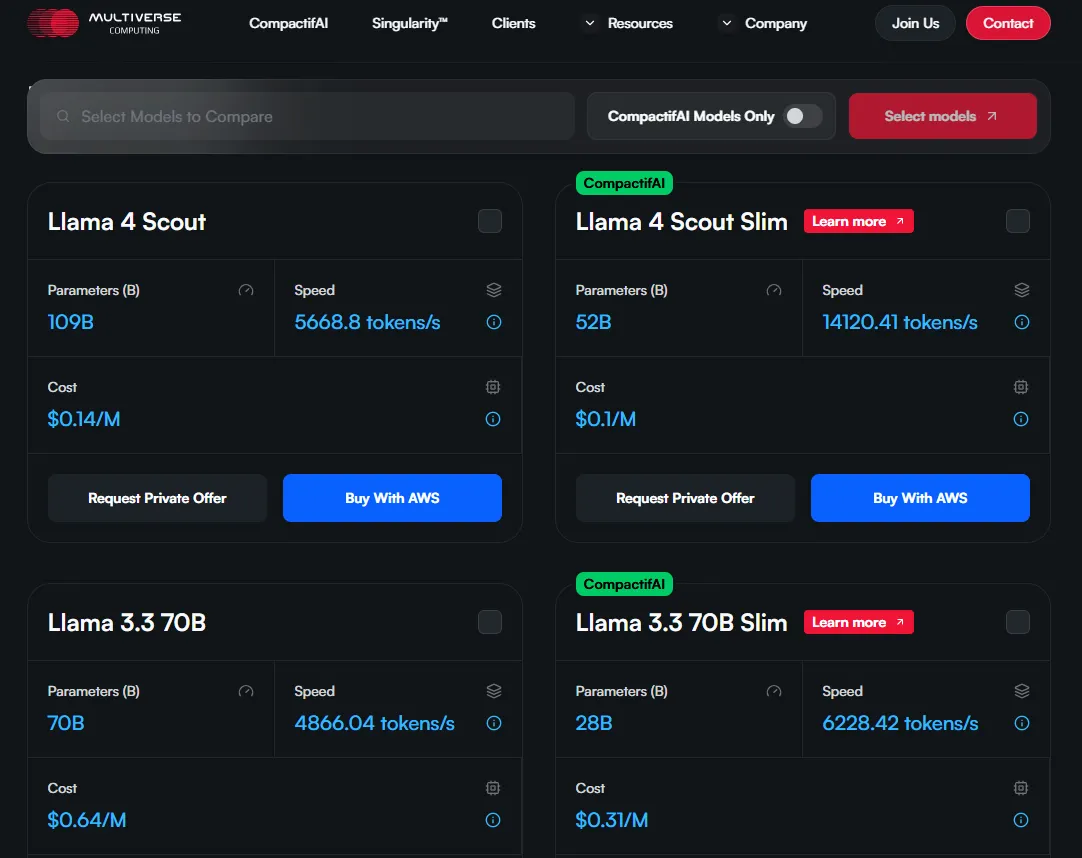
En su investigación, el equipo muestra que puedes reducir las necesidades de memoria del modelo Llama-2 7B en 93%, cortar el número de parámetros en 70%, acelerar el entrenamiento en 50%, y acelerar las respuestas (inferencia) en 25%, mientras solo pierdes 2-3% de precisión.
Los métodos tradicionales de reducción como cuantización (reducir la precisión como usar menos lugares decimales), poda (cortar neuronas menos importantes por completo, como podar ramas muertas de un árbol), o técnicas de destilación (entrenar un modelo más pequeño para imitar el comportamiento de uno más grande) ni siquiera están cerca de lograr estos números.
Multiverse ya atiende a más de 100 clientes incluyendo Bosch y el Banco de Canadá, aplicando sus algoritmos inspirados en cuántica más allá de la IA para optimización energética y modelado financiero.
El gobierno español co-invirtió €67 millones en marzo, empujando el financiamiento total por encima de $250 millones.
Multiverse Computing ya ofrece versiones comprimidas de modelos de código abierto como Llama y Mistral a través de AWS, y planea expandirse próximamente a DeepSeek R1 y otros modelos de razonamiento.
Los sistemas propietarios de OpenAI o Claude permanecen obviamente fuera de límites ya que no están disponibles para manipulación o estudio.
La promesa de la tecnología se extiende más allá de las medidas de ahorro de costos. La participación de HP Tech Ventures señala interés en el despliegue de IA en el borde: ejecutar modelos sofisticados localmente en lugar de servidores en la nube.
"El enfoque innovador de Multiverse tiene el potencial de dar vida a los beneficios de IA de rendimiento mejorado, personalización, privacidad y eficiencia de costos para empresas de cualquier tamaño", dijo Tuan Tran, Presidente de Tecnología e Innovación de HP.
Entonces, si te encuentras ejecutando DeepSeek R1 en tu smartphone algún día, podría ser gracias al trabajo pionero de estos investigadores vascos.
Editado por Josh Quittner y Sebastian Sinclair