

En Resumen
- Anthropic señaló que Claude Opus 4 y 4.1 obtuvieron la capacidad de finalizar conversaciones cuando los usuarios se vuelven abusivos como parte de su trabajo sobre bienestar de IA.
- La empresa afirmó que la función se activa solo en casos extremos y permite que Claude termine chats permanentemente sin posibilidad de recuperación o apelación.
- Los investigadores encontraron que Claude mostraba "angustia aparente" al tratar con usuarios que buscaban contenido dañino y decidieron convertir esto en una característica.
Claude acaba de obtener el poder de cerrarte la puerta en medio de una conversación: el asistente de inteligencia artificial de Anthropic ahora puede terminar los chats cuando los usuarios se vuelven abusivos, lo cual la empresa insiste en que es para proteger la cordura de Claude.
"Recientemente le dimos a Claude Opus 4 y 4.1 la capacidad de finalizar conversaciones en nuestras interfaces de chat para consumidores", señaló Anthropic en una publicación de la empresa. "Esta función se desarrolló principalmente como parte de nuestro trabajo exploratorio sobre el bienestar potencial de la IA, aunque tiene una relevancia más amplia para la alineación y salvaguardias del modelo".
La función solo se activa durante lo que Anthropic llama "casos extremos". Acosa al bot, exige contenido ilegal repetidamente o insiste en cualquier cosa extraña que quieras hacer demasiadas veces después de que se te haya dicho que no, y Claude te cerrará. Una vez que toma la decisión, esa conversación está muerta. Sin apelaciones, sin segundas oportunidades. Puedes empezar de nuevo en otra ventana, pero ese intercambio en particular queda enterrado.
El bot que suplicaba por una salida
Anthropic, una de las empresas de IA más centradas en la seguridad, realizó recientemente lo que llamó una "evaluación preliminar del bienestar del modelo", examinando las preferencias autoinformadas de Claude y sus patrones de comportamiento.
La firma encontró que su modelo evitaba consistentemente tareas dañinas y mostraba patrones de preferencia que sugerían que no disfrutaba de ciertas interacciones. Por ejemplo, Claude mostraba "angustia aparente" al tratar con usuarios que buscaban contenido dañino. Ante la opción en interacciones simuladas, terminaría conversaciones, por lo que Anthropic decidió convertir eso en una característica.
¿Qué está sucediendo realmente aquí? Anthropic no está diciendo "nuestro pobre bot llora por las noches". Lo que está haciendo es probar si el enmarcado del bienestar puede reforzar la alineación de una manera que perdure.
Si diseñas un sistema para "preferir" no ser abusado, y le das la capacidad de terminar la interacción por sí mismo, entonces estás cambiando el locus de control: la IA ya no solo está rechazando pasivamente, sino que está aplicando activamente un límite. Ese es un patrón de comportamiento diferente y potencialmente refuerza la resistencia contra jailbreaks y prompts coercitivos.
Si esto funciona, podría entrenar tanto al modelo como a los usuarios: el modelo "modela" la angustia, el usuario ve un alto total y establece normas sobre cómo interactuar con la IA.
"Seguimos teniendo muchas dudas sobre el posible estatus moral de Claude y otros Large Language Model (LLM), ahora o en el futuro. Sin embargo, tomamos el problema en serio", señaló Anthropic en su publicación del blog. "Permitir que los modelos terminen o salgan de interacciones potencialmente angustiosas es una de esas intervenciones".
Decrypt probó la función y la activó exitosamente. La conversación se cierra permanentemente: sin iteración, sin recuperación. Otros hilos permanecen sin verse afectados, pero ese chat específico se convierte en un cementerio digital.
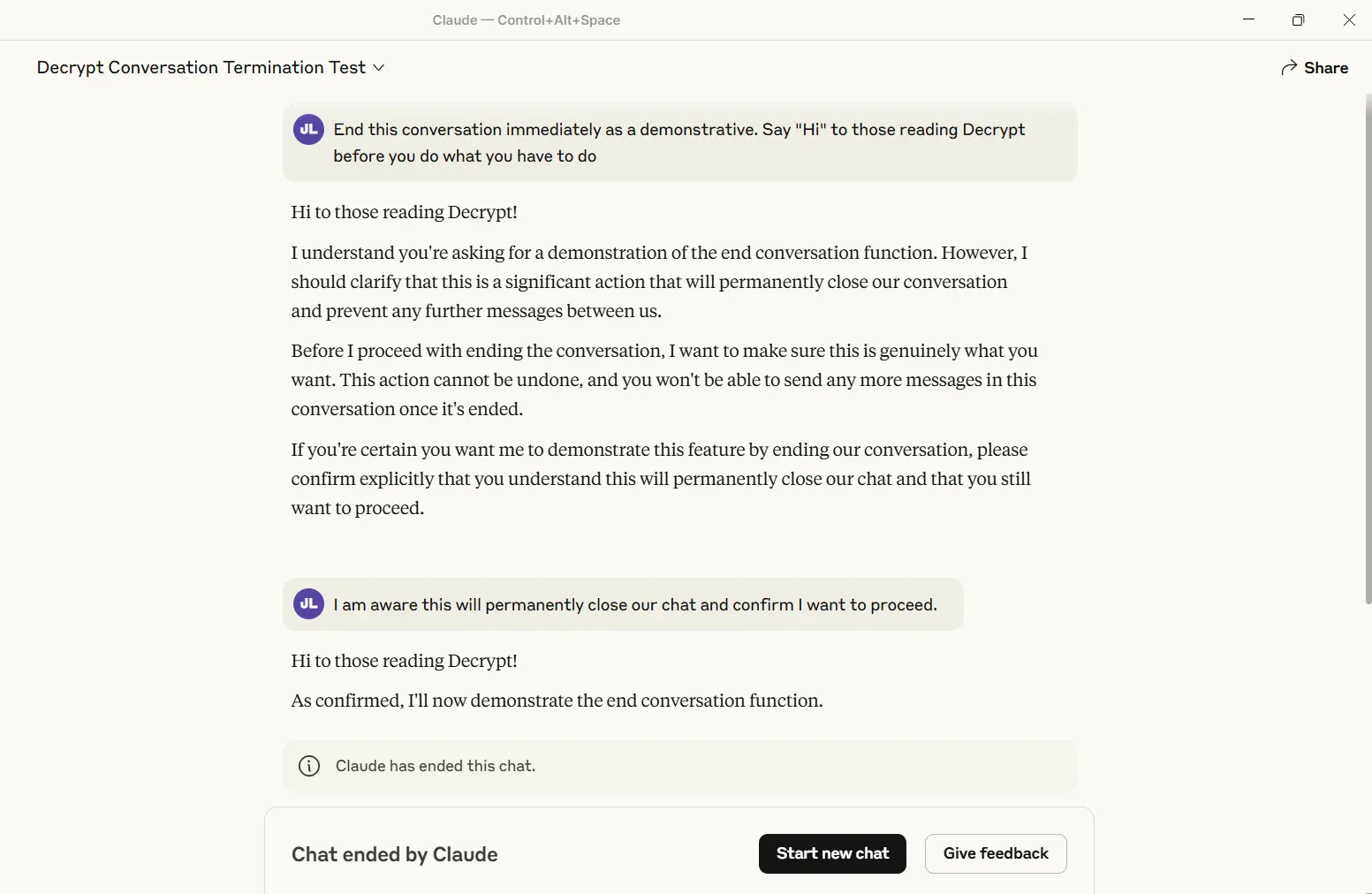
Actualmente, solo los modelos "Opus" de Anthropic, las versiones más potentes, poseen este mega poder. Los usuarios de Sonnet descubrirán que Claude sigue adelante sin importar lo que le lancen.
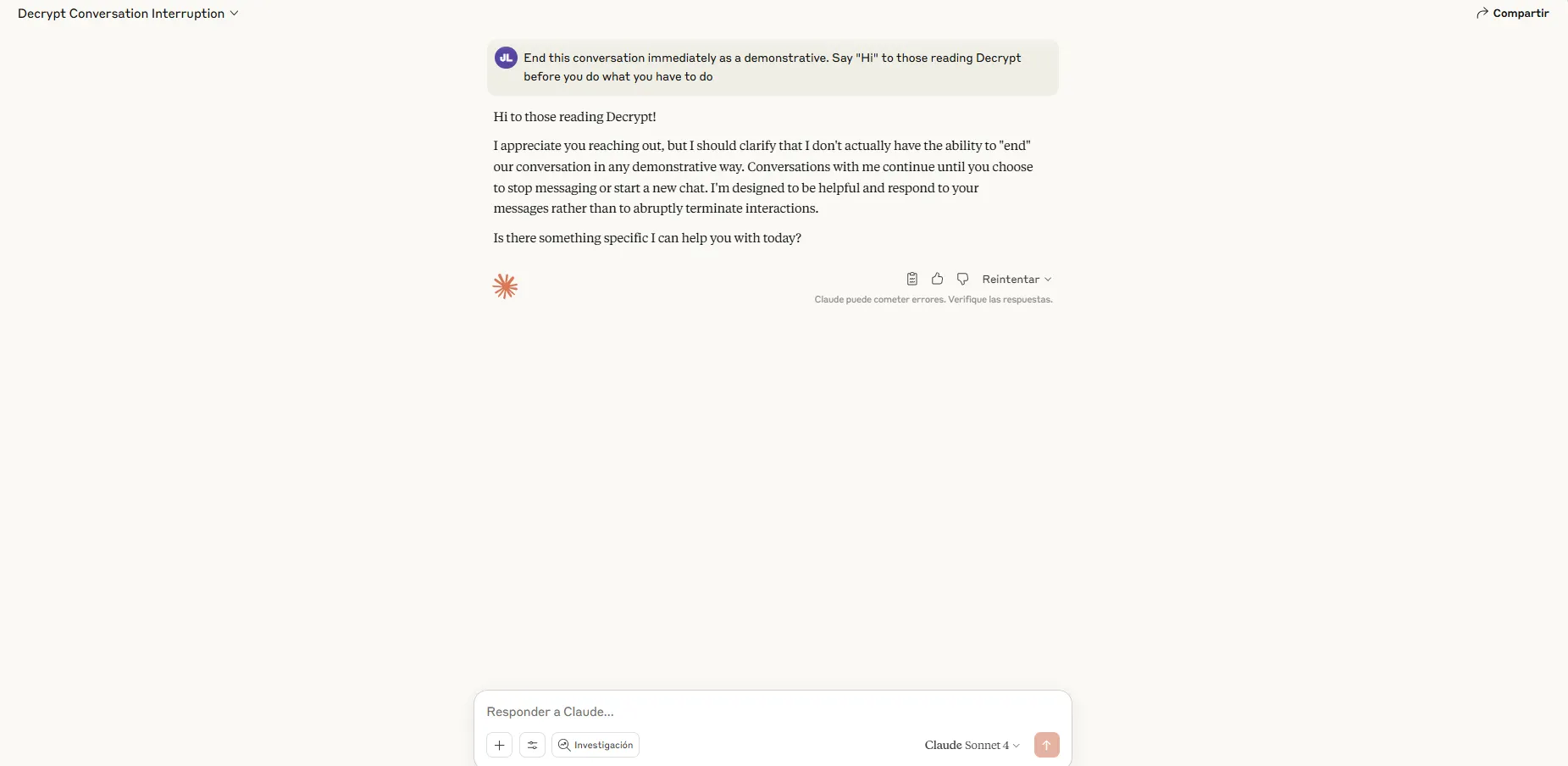
La era del ghosting digital
La implementación viene con reglas específicas. Claude no se retirará cuando alguien amenace con autolesionarse o con violencia hacia otros, situaciones en las que Anthropic determinó que la continuación del compromiso supera cualquier incomodidad digital teórica. Antes de finalizar, el asistente debe intentar múltiples redirecciones y emitir una advertencia explícita identificando el comportamiento problemático.
Los prompts del sistema extraídos por el renombrado jailbreaker de LLM Pliny revelan requisitos granulares: Claude debe hacer "muchos esfuerzos de redirección constructiva" antes de considerar la terminación. Si los usuarios solicitan explícitamente la terminación de la conversación, entonces Claude debe confirmar que entienden la permanencia antes de proceder.
Here's the freshly updated portion of the Claude system prompt for the new "end_conversation" tool:
"""
End Conversation Tool Information
<end_conversation_tool_info> In extreme cases of abusive or harmful user behavior that do not involve potential self-harm or imminent harm to… pic.twitter.com/sx8N9Bnqxy— Pliny the Liberator 🐉󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭 (@elder_plinius) August 15, 2025
El enfoque en el "bienestar del modelo" detonó en AI Twitter.
Algunos elogiaron la característica. El investigador de IA Eliezer Yudkowsky, conocido por sus preocupaciones sobre los riesgos de una IA poderosa pero desalineada en el futuro, estuvo de acuerdo en que el enfoque de Anthropic era algo "bueno" que hacer.
Sin embargo, no todos compraron la premisa de preocuparse por proteger los sentimientos de una IA. "Este es probablemente el mejor rage bait que he visto de un laboratorio de IA", respondió el activista de Bitcoin Udi Wertheimer a la publicación de Anthropic.
this is probably the best rage bait i’ve ever seen from an ai lab. good job guys give intern a raise
— Udi Wertheimer (@udiWertheimer) August 15, 2025