

En Resumen
- Investigadores desarrollaron Delphi-2M, un sistema de IA que predice más de 1.000 enfermedades hasta 20 años antes de que aparezcan síntomas con 76% de precisión.
- El modelo superó calculadores de riesgo existentes al evaluar simultáneamente todo el espectro de enfermedades humanas usando datos de 402.799 participantes británicos.
- Los científicos señalaron que el sistema reveló cómo las enfermedades se influencian mutuamente, mostrando patrones de agrupamiento en condiciones de salud mental.
Investigadores han desarrollado un sistema de IA que predice el riesgo de desarrollar más de 1.000 enfermedades hasta 20 años antes de que aparezcan los síntomas, según un estudio publicado en Nature esta semana.
El modelo, llamado Delphi-2M, logró una precisión del 76% para predicciones de salud a corto plazo y mantuvo un 70% de precisión incluso al prever una década en el futuro.
Superó a los calculadores de riesgo de enfermedades individuales existentes al mismo tiempo que evaluaba los riesgos en todo el espectro de enfermedades humanas.
"La progresión de la enfermedad humana a lo largo de la edad se caracteriza por períodos de salud, episodios de enfermedad aguda y también de debilitamiento crónico, a menudo manifestándose como grupos de comorbilidad", escribieron los investigadores. "Pocos algoritmos son capaces de predecir el espectro completo de la enfermedad humana, que reconoce más de 1.000 diagnósticos en el nivel superior del sistema de codificación de la Décima Revisión de la Clasificación Internacional de Enfermedades (CIE-10)".
El sistema aprendió estos patrones de 402.799 participantes del Biobanco del Reino Unido, luego demostró su valor en 1,9 millones de registros de salud daneses sin ningún entrenamiento adicional.
Antes de que empieces a frotarte las manos con la idea de tu propio predictor médico, debes saber que por ahora no puedes probar Delphi-2M tú mismo, al menos no exactamente.
El modelo entrenado y sus pesos están bloqueados detrás de los procedimientos de acceso controlado de Banco de Datos del Reino Unido, lo que significa que solo los investigadores pueden usarlo. El código base para entrenar su propia versión está en GitHub bajo una licencia del MIT, por lo que técnicamente podrías construir tu propio modelo, pero necesitarías acceso a conjuntos de datos médicos masivos para que funcione.
Por ahora, esto sigue siendo una herramienta de investigación, y no una aplicación para consumidores.
Detrás del telón
La tecnología funciona tratando los historiales médicos como secuencias, al igual que ChatGPT procesa texto.
Cada diagnóstico, registrado con la edad en que ocurrió por primera vez, se convierte en un token. El modelo lee este "lenguaje" médico y predice lo que vendrá a continuación.
Con la información y el entrenamiento adecuados, puedes predecir el próximo token (en este caso, la próxima enfermedad) y el tiempo estimado antes de que se genere ese "token" (cuánto tiempo pasará hasta que te enfermes si ocurre el conjunto de eventos más probable).
Para un adulto de 60 años con diabetes y presión arterial alta, Delphi-2M podría predecir un aumento de 19 veces en el riesgo de cáncer de páncreas. Agregue un diagnóstico de cáncer de páncreas a ese historial, y el modelo calcula que el riesgo de mortalidad aumenta casi diez mil veces.
La arquitectura del transformador detrás de Delphi-2M representa el viaje de salud de cada persona como una línea de tiempo de códigos de diagnóstico, factores de estilo de vida como fumar e IMC, y datos demográficos. Los tokens de relleno "Sin evento" llenan los espacios entre visitas médicas, enseñando al modelo que el simple paso del tiempo cambia el riesgo base.
Esto también es similar a cómo los LLM normales pueden entender el texto incluso si se pierden algunas palabras o incluso frases.
Cuando se probó con herramientas clínicas establecidas, Delphi-2M igualó o superó su rendimiento. Para la predicción de enfermedades cardiovasculares, logró un AUC de 0,70 en comparación con 0,69 para AutoPrognosis y 0,71 para QRisk3. Para la demencia, alcanzó 0,81 frente a 0,81 para UKBDRS. La diferencia clave: esas herramientas predicen condiciones individuales. Delphi-2M evalúa todo a la vez.
Más allá de las predicciones individuales, el sistema genera trayectorias de salud sintéticas completas.
Partiendo de datos a los 60 años, puede simular miles de futuros de salud posibles, produciendo estimaciones de carga de enfermedad a nivel de población precisas dentro de márgenes estadísticos. Un conjunto de datos sintéticos entrenó un modelo secundario de Delphi que logró una precisión del 74%, solo tres puntos porcentuales por debajo del original.
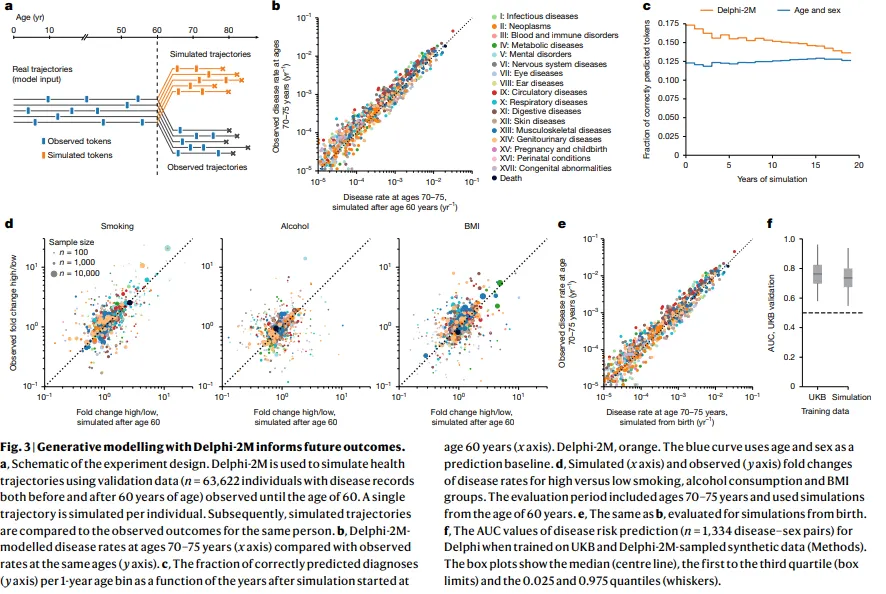
El modelo reveló cómo las enfermedades se influencian mutuamente con el tiempo. Los cánceres aumentaron el riesgo de mortalidad con una "vida media" de varios años, mientras que el efecto de la septicemia disminuyó bruscamente, volviendo a niveles cercanos a la línea base en cuestión de meses. Las condiciones de salud mental mostraron efectos persistentes de agrupamiento, con un diagnóstico prediciendo fuertemente otros en esa categoría años más tarde.
Limitaciones
El sistema tiene sus límites. Sus predicciones a 20 años caen a alrededor del 60-70% de precisión en general, pero dependerá de qué tipo de enfermedad y condiciones intente analizar y pronosticar.
"Para el 97% de los diagnósticos, el AUC fue mayor que 0,5, lo que indica que la gran mayoría siguió patrones con al menos cierta previsibilidad", dice el estudio, agregando más adelante que "los valores promedio de AUC de Delphi-2M disminuyen de un promedio de 0,76 a 0,70 después de 10 años", y que "en el primer año de muestreo, hay en promedio un 17% de tokens de enfermedades que se predicen correctamente, y esto disminuye a menos del 14% 20 años después".
En otras palabras, este modelo es bastante bueno para predecir cosas bajo escenarios relevantes, pero mucho puede cambiar en 20 años, por lo que no es Nostradamus.
Enfermedades raras y condiciones ambientales altamente desafiantes resultan más difíciles de predecir. El sesgo demográfico de la UK Biobank—principalmente voluntarios blancos, educados y relativamente sanos—introduce un sesgo que los investigadores reconocen que necesita ser abordado.
La validación danesa reveló otra limitación: Delphi-2M aprendió algunas peculiaridades en la recopilación de datos específicas del Reino Unido. Las enfermedades registradas principalmente en entornos hospitalarios parecían estar infladas artificialmente, contradiciendo los datos registrados por la población danesa.
El modelo predijo la septicemia a ocho veces la tasa normal para cualquier persona con datos hospitalarios previos, en parte porque el 93% de los diagnósticos de septicemia de la UK Biobank provenían de registros hospitalarios.
Los investigadores entrenaron a Delphi-2M utilizando una arquitectura GPT-2 modificada con 2,2 millones de parámetros—pequeña en comparación con los modelos de lenguaje modernos pero suficiente para la predicción médica. Las modificaciones clave incluyeron la codificación continua de la edad en lugar de marcadores de posición discretos y un modelo de tiempo de espera exponencial para predecir cuándo ocurrirían los eventos, no solo qué sucedería.
Cada trayectoria de salud en los datos de entrenamiento contenía un promedio de 18 tokens de enfermedades que abarcaban desde el nacimiento hasta los 80 años. El sexo, las categorías de IMC, el estado de fumador y el consumo de alcohol añadieron contexto.
El modelo aprendió a ponderar automáticamente estos factores, descubriendo que la obesidad aumentaba el riesgo de diabetes mientras que fumar elevaba las probabilidades de cáncer, relaciones que la medicina ha establecido desde hace tiempo pero que surgieron sin programación explícita. Realmente es un LLM para condiciones de salud.
Para la implementación clínica, quedan varios obstáculos.
El modelo necesita validación en poblaciones más diversas, por ejemplo, los estilos de vida y hábitos de las personas de Nigeria, China y América pueden ser muy diferentes, lo que hace que el modelo sea menos preciso.
Además, las preocupaciones de privacidad sobre el uso de historiales de salud detallados requieren un manejo cuidadoso. La integración con los sistemas de atención médica existentes plantea desafíos técnicos y regulatorios.
Pero las posibles aplicaciones van desde identificar candidatos para pruebas que no cumplen con criterios basados en la edad hasta modelar intervenciones en la salud de la población. Las compañías de seguros, las empresas farmacéuticas y las agencias de salud pública pueden tener intereses obvios.
Delphi-2M se une a una creciente familia de modelos médicos basados en transformadores. Algunos ejemplos incluyen la herramienta PDGrapher de Harvard para predecir combinaciones de genes y medicamentos que podrían revertir enfermedades como el Parkinson o el Alzheimer, un LLM específicamente entrenado en conexiones de proteínas, el modelo AlphaGenome de Google entrenado en pares de ADN, y otros.
Lo que hace que Delphi-2M sea tan interesante y diferente es su amplio alcance de acción, la gran cantidad de enfermedades cubiertas, su largo horizonte de predicción y su capacidad para generar datos sintéticos realistas que preservan las relaciones estadísticas mientras protegen la privacidad individual.
En otras palabras: "¿Cuánto tiempo me queda?" pronto podría ser menos una pregunta retórica y más un punto de datos predecible.