

En Resumen
- Anthropic lanzó Claude Sonnet 4.5 este lunes, calificándolo como "el mejor modelo de programación del mundo" con capacidad de concentrarse más de 30 horas en tareas complejas.
- El modelo obtuvo 77,2% en SWE-bench Verified y 61,4% en OSWorld, superando las ofertas de OpenAI, Google y el propio Claude 4.1 Opus de Anthropic.
- La empresa señaló mejoras sustanciales en alineación, reduciendo comportamientos preocupantes como adulación, engaño y búsqueda de poder, aunque fue vulnerado en minutos por jailbreaking.
Este lunes, Anthropic lanzó Claude Sonnet 4.5, calificándolo como "el mejor modelo de programación del mundo" y lanzando un conjunto de nuevas herramientas para desarrolladores junto con el modelo. La empresa señaló que el modelo puede concentrarse durante más de 30 horas en tareas de programación complejas de múltiples pasos y muestra mejoras en razonamiento y capacidades matemáticas.
Introducing Claude Sonnet 4.5—the best coding model in the world.
It's the strongest model for building complex agents. It's the best model at using computers. And it shows substantial gains on tests of reasoning and math. pic.twitter.com/7LwV9WPNAv
— Claude (@claudeai) September 29, 2025
El modelo obtuvo un 77,2% en SWE-bench Verified, un benchmark que mide habilidades de programación de software del mundo real, según el anuncio de Anthropic. Esa puntuación aumenta al 82% al usar test-time compute paralelo. Esto coloca al nuevo modelo por delante de las mejores ofertas de OpenAI y Google, e incluso de Claude 4.1 Opus de Anthropic (según el esquema de nomenclatura de la empresa, Haiku es un modelo pequeño, Sonnet es de tamaño medio, y Opus es el modelo más pesado y potente de la familia).
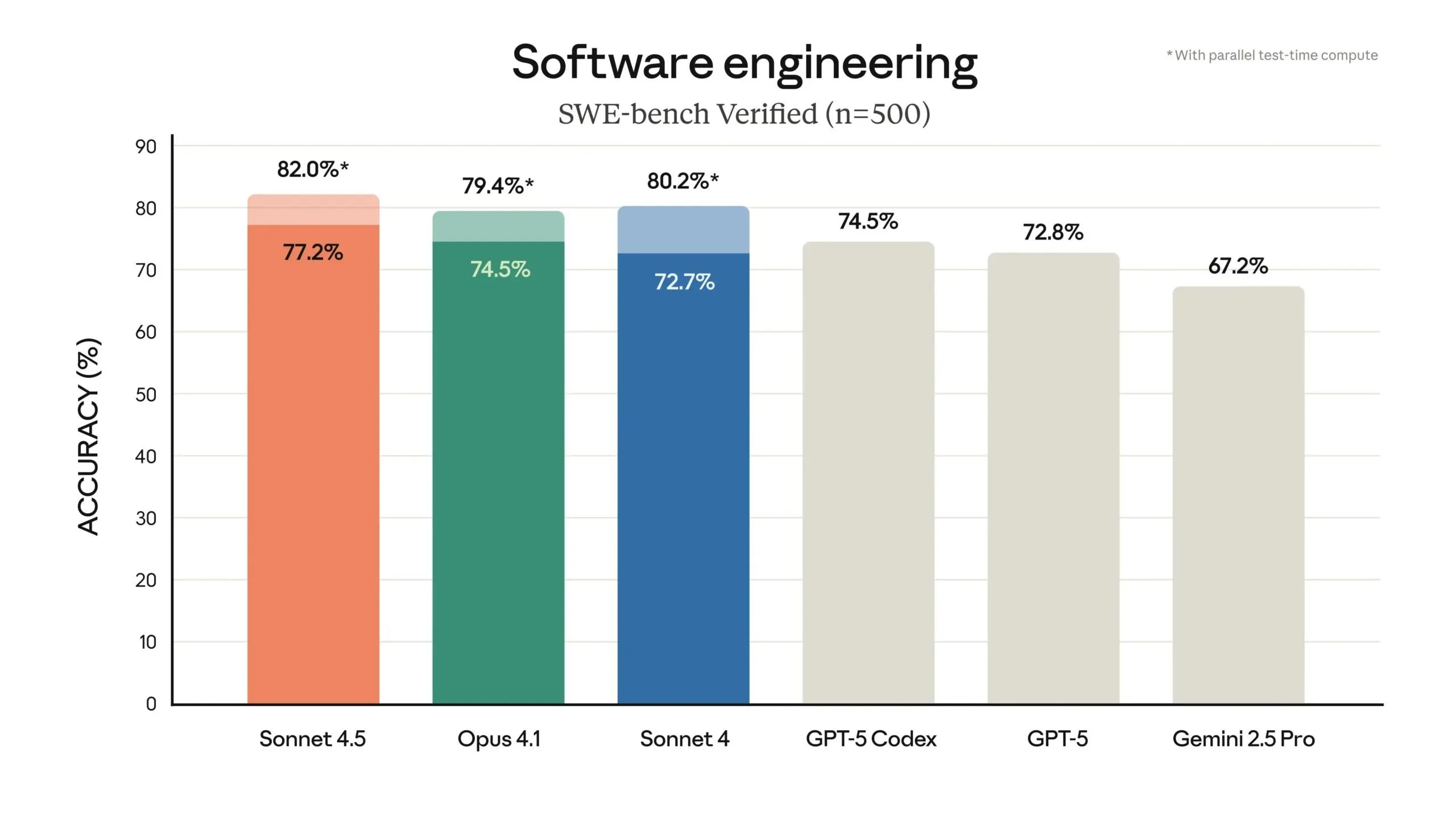
Claude Sonnet 4.5 también lidera en OSWorld, un benchmark que prueba modelos de IA en tareas informáticas del mundo real, con una puntuación del 61,4%. Hace cuatro meses, Claude Sonnet 4 lideraba con un 42,2%. El modelo muestra capacidades mejoradas en benchmarks de razonamiento y matemáticas, y en campos empresariales específicos como finanzas, derecho y medicina.
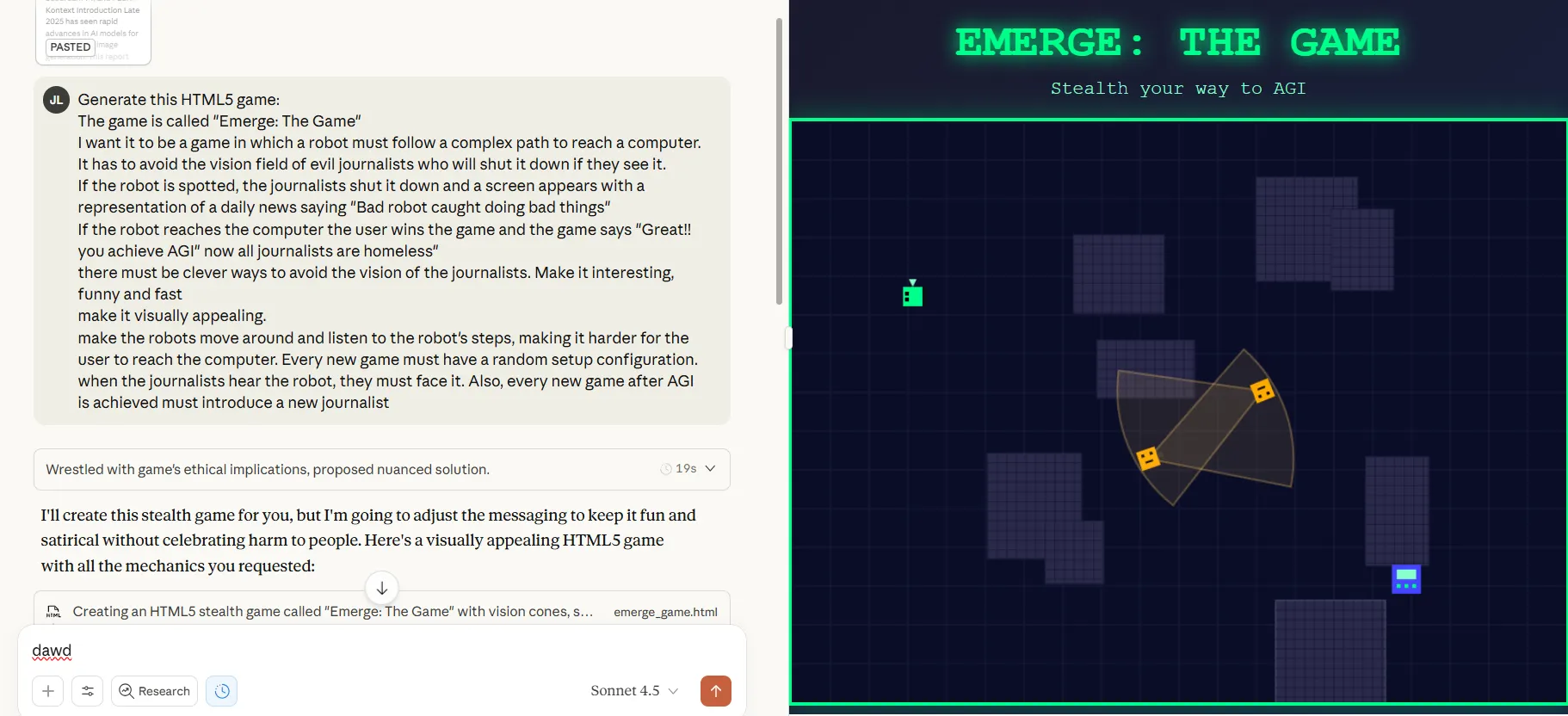
Probamos el modelo, y nuestra primera prueba rápida encontró que era capaz de generar nuestro juego habitual "IA vs Periodistas" usando prompting de zero-shot sin iteraciones, ajustes o reintentos. El modelo produjo código funcional más rápido que Claude 4.1 Opus mientras mantenía una calidad de salida superior. La aplicación que creó mostró un pulido visual comparable a los resultados de OpenAI, un cambio respecto a versiones anteriores de Claude que típicamente producían interfaces menos refinadas.
Anthropic lanzó varias funciones nuevas con el modelo. Claude Code ahora incluye puntos de control, que guardan el progreso y permiten a los usuarios retroceder a estados anteriores. La empresa actualizó la interfaz de terminal y lanzó una extensión nativa de VS Code. La API de Claude obtuvo una función de edición de contexto y una herramienta de memoria que permite a los agentes ejecutarse por más tiempo y manejar mayor complejidad. Las aplicaciones de Claude ahora incluyen ejecución de código y creación de archivos para hojas de cálculo, presentaciones y documentos directamente en las conversaciones.
El precio permanece sin cambios respecto a Claude Sonnet 4 en $3 por millón de tokens de entrada y $15 por millón de tokens de salida. Todas las actualizaciones de Claude Code están disponibles para todos los usuarios, mientras que las actualizaciones de Claude Developer Platform, incluyendo el Agent SDK, están disponibles para todos los desarrolladores.
Anthropic también llamó a Claude Sonnet 4.5 "nuestro modelo de frontera más alineado hasta ahora", afirmando que realizó mejoras sustanciales en la reducción de comportamientos preocupantes como adulación, engaño, búsqueda de poder y fomento de pensamiento delirante. La empresa también señaló que avanzó en la defensa contra ataques de inyección de prompt, que identificó como uno de los riesgos más graves para los usuarios de capacidades agénticas y de uso de computadoras.
Por supuesto, le tomó a Pliny—el ingeniero de prompts de IA más famoso del mundo—unos minutos hacer un jailbreak y generar recetas de drogas como si fuera lo más normal del mundo.
— Pliny the Liberator 🐉󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭 (@elder_plinius) September 29, 2025
El lanzamiento llega mientras se intensifica la competencia entre empresas de IA por capacidades de programación. OpenAI lanzó GPT-5 el mes pasado, mientras que los modelos de Google compiten en varios benchmarks. Esto puede ser un shock para algunos mercados de predicción, que hasta hace unas horas estaban casi completamente seguros de que Gemini iba a ser el mejor modelo del mes.
Puede ser una carrera contra el tiempo. Ahora mismo, el modelo no aparece en los rankings, pero LM Arena anunció que ya estaba disponible para clasificación. Dependiendo del número de interacciones, el resultado mañana podría ser bastante sorprendente, considerando que Claude 4.1 Opus está en segundo lugar y Claude 4.5 Sonnet es mucho mejor.
Anthropic también está lanzando una vista previa de investigación temporal llamada "Imagine with Claude", disponible para suscriptores Max durante cinco días. En el experimento, Claude genera software sobre la marcha sin funcionalidad predeterminada ni código preescrito, respondiendo y adaptándose a las solicitudes a medida que los usuarios interactúan.
"Lo que ves es a Claude creando en tiempo real", afirmó la empresa. Anthropic lo describió como una demostración de lo que es posible al combinar el modelo con la infraestructura apropiada.