

En Resumen
- Conoce todo sobre Stable Diffusion, una herramienta de inteligencia artificial de código abierto que genera imágenes a partir de detalladas descripciones de texto conocidas como "prompts".
- El proceso de creación de imágenes involucra convertir imagenes aleatorias en una imagen discernible siguiendo los prompts. Cuanto más detallada la descripción, Mejor será el resultado.
- Puedes instalar diferentes modelos, extensiones y complementos para expandir las capacidades de Stable Diffusion.

Ya sea que seas un artista digital en busca de inspiración fresca o simplemente un sujeto cualquiera con un hambre insaciable de imágenes, Stable Diffusion está listo para convertirse en tu nueva herramienta de referencia. ¿La mejor parte? Es de código abierto y completamente gratuito, invitando a todos a ponerse sus sombreros creativos. Pero ten cuidado: como cualquier artista habilidoso, tiene el potencial de producir contenido adulto o NSFW, si eso es lo que requiere tu 'recipe' o receta.
Stable Diffusion es una herramienta de IA generativa de texto a imagen, esto significa que traduce palabras en imágenes. El proceso es similar a enviar un detallado informe a un maestro pintor y esperar el regreso de una obra de arte creada meticulosamente.
Considera a Stable Diffusion tu aliado creativo personal basado en IA. Diseñado principalmente para generar imágenes a partir de indicaciones de texto, este modelo de aprendizaje profundo va más allá de una sola función. También se puede utilizar para rellenar (alterar secciones de una imagen), ampliar (expandir una imagen más allá de sus bordes existentes) y traducir imágenes basadas en indicaciones de texto conocidas como "prompts". Esta versatilidad equivale a tener un artista polifacético a tu disposición.
La mecánica de Stable Diffusion
Stable Diffusion funciona sobre la base de un modelo de aprendizaje profundo o "deep learning model" que crea imágenes a partir de descripciones de texto. Su base es un proceso de difusión, donde una imagen se transforma desde un ruido aleatorio en una imagen coherente a través de una serie de pasos. El modelo está entrenado para guiar cada fase, dirigiendo así todo el proceso desde el inicio hasta el final, según la indicación de texto proporcionada.
La idea central detrás de Stable Diffusion es la conversión del ruido (aleatoriedad) en una imagen. El modelo inicia el proceso con un montón de ruido aleatorio (piensa en una versión en color del ruido blanco de un televisor sin señal) que luego se va refinando gradualmente, influenciado por la indicación de texto, hasta convertirse en una imagen discernible. Este refinamiento se realiza de manera sistemática, disminuyendo gradualmente el ruido e intensificando los detalles hasta que emerge una imagen de alta calidad.
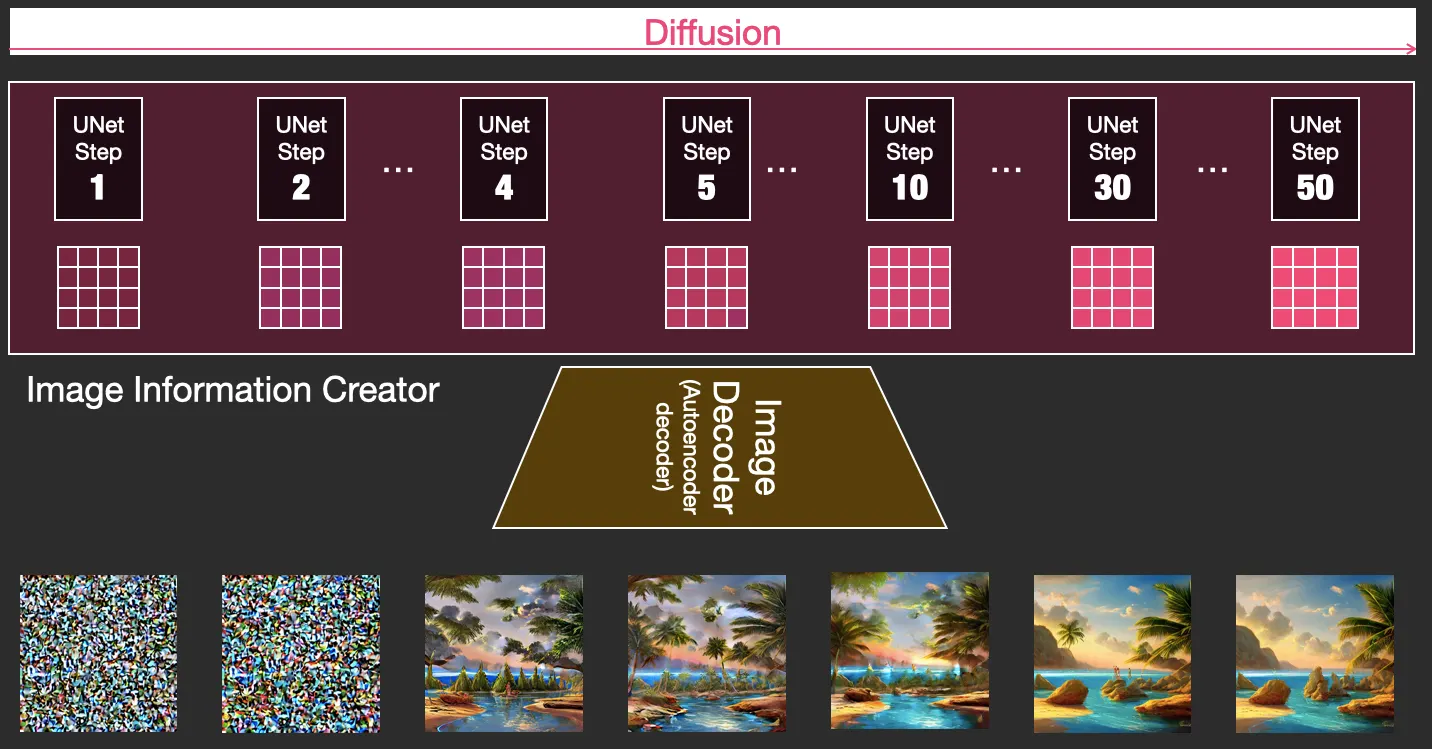
A medida que comienza el proceso de difusión, las etapas preliminares dictan en gran medida la composición general de la imagen, y las alteraciones posteriores de las palabras clave solo afectan a pequeñas porciones. Esto enfatiza la necesidad de prestar atención cuidadosa al peso y la programación de sus palabras clave para lograr el resultado deseado.
Ventajas de Stable Diffusion
Stable Diffusion destaca por crear imágenes detalladas y de alta calidad, diseñadas a medida para prompts específicos. Navega fácilmente entre diferentes estilos artísticos, fusiona técnicas de diferentes artistas y transita sin problemas entre palabras clave variadas.
A diferencia de sus contrapartes como MidJourney, Stable Diffusion es gratuito, lo cual es una ventaja para tu presupuesto. También es de código abierto, lo que significa que puedes modificarlo como desees. Ya sea que desees crear paisajes futuristas o imágenes inspiradas en anime, Stable Diffusion tiene un modelo para eso. Más adelante profundizaremos en cómo descargar y adaptar estos modelos a tus preferencias.
Además puedes ejecutarlo sin conexión a internet, eliminando la necesidad de una conexión constante o acceso a un servidor, lo que lo convierte en una herramienta valiosa para usuarios preocupados por la privacidad.
Sin embargo, hay algunas desventajas
A diferencia de MidJourney, Stable Diffusion tiene una curva de aprendizaje pronunciada. Para generar imágenes realmente sorprendentes, debes interactuar con modelos personalizados, complementos y un poco de ingeniería de indicaciones. Es un poco como el tema de Windows vs Linux.
Además, el modelo ocasionalmente puede mostrar asociaciones imprevistas, lo que lleva a resultados inesperados. Un pequeño error en la indicación puede provocar desviaciones significativas en la salida. Por ejemplo, especificar el color de ojos en una indicación podría influir involuntariamente en la etnia de los personajes generados (por ejemplo, los ojos azules suelen asociarse a personas caucásicas). Por lo tanto, es necesario tener un profundo conocimiento de su funcionamiento para obtener resultados óptimos.
Además, requiere una cantidad extensa de detalles en la indicación para ofrecer resultados impresionantes. A diferencia de MidJourney, que funciona bien con indicaciones como "una mujer hermosa caminando en el parque", Stable Diffusion requiere una descripción completa de todo lo que deseas (o no deseas) ver en tu imagen. Prepárate para indicaciones largas y detalladas.
Stable Diffusion en Funcionamiento
Existen varias formas de ejecutar Stable Diffusion, ya sea a través de plataformas basadas en la nube o directamente en tu máquina local.
Estas son algunas de las plataformas en línea que te permiten probarlo en la nube:
- Leonardo AI: Te permite experimentar con diferentes modelos, algunos de los cuales emulan la estética de MidJourney.
- Sea Art: Un buen lugar para probar muchos modelos de Stable Diffusion con complementos y otras herramientas avanzadas.
- Mage Space: Ofrece las versiones de Stable Diffusion v1.5 y v2.1. Aunque tiene una amplia galería de otros modelos, requiere membresía.
- Lexica: Una plataforma fácil de usar que te guía para descubrir indicaciones óptimas para tus imágenes.
- Google Colabs: Otra opción accesible.
Sin embargo, si optas por una instalación local, asegúrate de que tu computadora tenga las capacidades necesarias.
Requisitos del sistema
Para ejecutar Stable Diffusion localmente, tu PC debe tener Windows 10 o superior, y al menos una tarjeta de video Nvidia discreta (GPU) con al menos 4 GB de VRAM, tener 16 GB de RAM y 10 GB de espacio libre.
Para una experiencia óptima, se recomienda una GPU RTX con 12GB de vRAM, 32 GB de RAM y un SSD de alta velocidad. El espacio en disco dependerá de tus necesidades específicas: cuanto más modelos y complementos planees usar, más espacio necesitarás. Por lo general, los modelos necesitan entre 2GB y 5GB de espacio.
Navegando Por Stable Diffusion con Automatic 1111
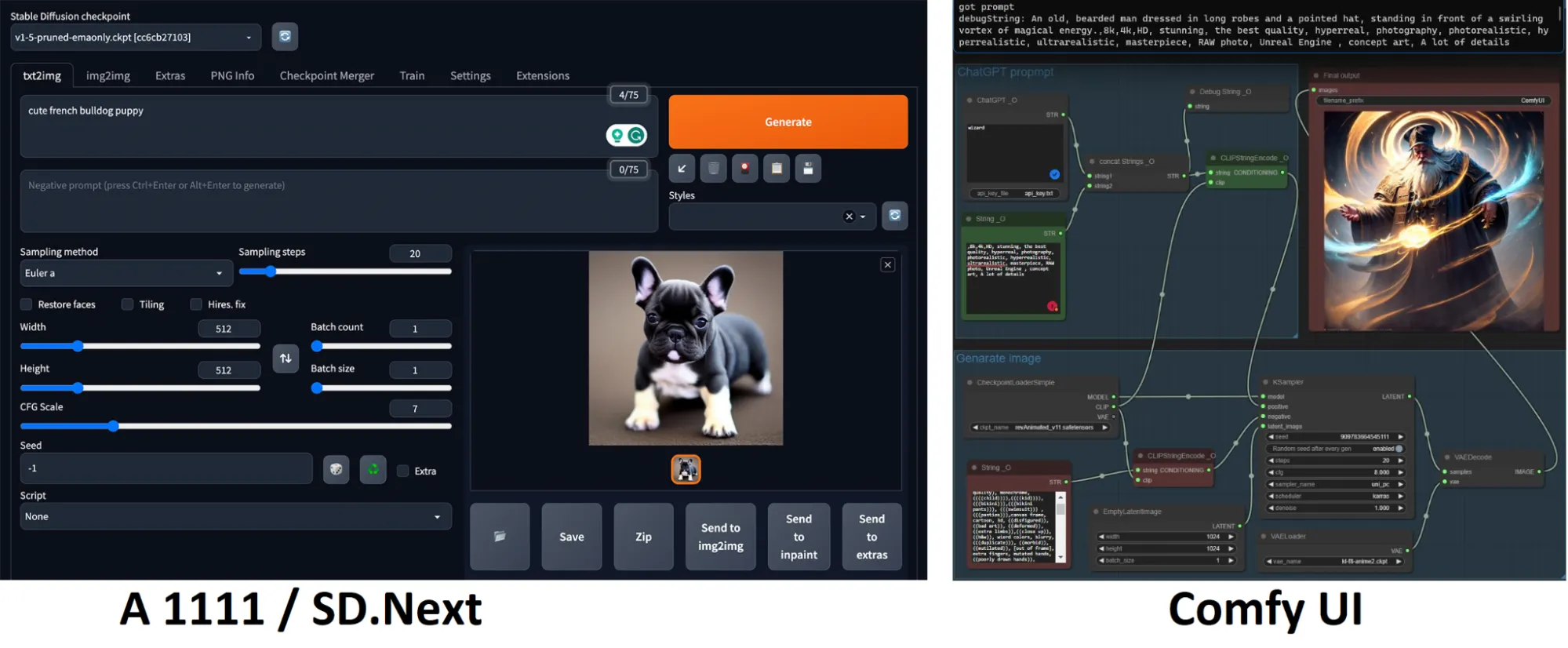
A medida que te embarcas en tu viaje con Stable Diffusion, elegir la interfaz gráfica de usuario (GUI) adecuada se vuelve crucial. Para el outpainting (una técnica de inteligencia artificial que permite expandir o aumentar una imagen más allá de sus bordes o límites originales), Invoke AI lidera el grupo, mientras que SD.Next defiende la eficiencia.
Por otra parte, ComfyUI es una opción súper liviana basada en nodos que ha estado ganando mucha popularidad últimamente debido a su compatibilidad con el nuevo SDXL. Sin embargo, Automatic 1111, con su popularidad y facilidad de uso, se posiciona como la opción más preferida. Así que, vamos a adentrarnos en cómo puedes comenzar con Automatic 1111.
Configuración de Automatic 1111
El proceso de instalación de Automatic 1111 es sencillo, gracias al instalador de un solo clic disponible en este repositorio. Dirígete a la sección "assets" de la página de Github, descarga el archivo .exe y ejecútalo. Esto, te puede llevar un momento, así que se paciente y no te desesperes.
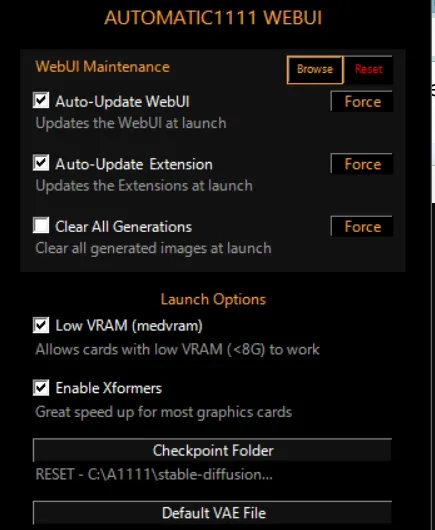
Una vez instalado correctamente, se creará un acceso directo de 'A1111 WebUI' en una carpeta recién abierta. Considera anclarlo a tu barra de tareas o crear un acceso directo en el escritorio para acceder más fácilmente. Al hacer clic en este acceso directo, se iniciará Stable Diffusion, listo para tus comandos creativos.
Sería una buena idea marcar las casillas de: Actualización automática de la interfaz web (mantener el programa actualizado), Actualización automática de extensiones (mantener los complementos y herramientas de terceros actualizados), y, si tu PC no es muy potente, también debes activar la opción de VRam baja (medvram) y la opción de habilitar Xformers.
Entendiendo la interfaz de usuario
Una vez que tengas Stable Diffusion con A1111 instalado, esto es lo que verás cuando lo abras
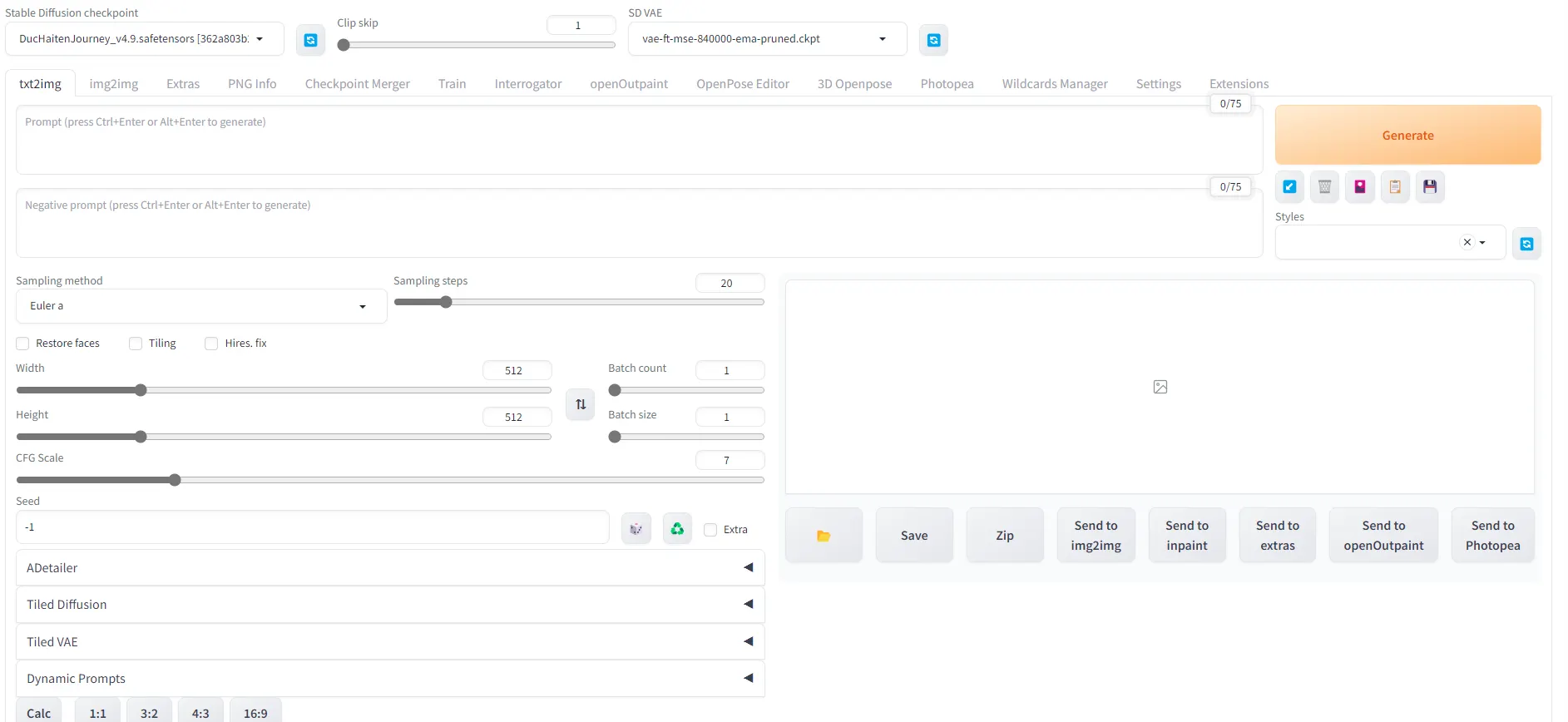
Pero no te intimides. Aquí tienes un breve recorrido por la interfaz al ejecutar Stable Diffusion:
- Checkpoint or Model: Básicamente, el corazón detrás de tu operación de imagen de IA, estos pesos pre-entrenados de Stable Diffusion se pueden comparar con tener diversos artistas entrenados en diferentes géneros. Uno podría ser experto en anime, mientras que otro se destaca en el realismo. Tu elección aquí establece el estilo artístico de tu imagen.
- Positive Prompt: Aquí es donde articulas lo que deseas en tu imagen.
- Negative Prompt: Especifica lo que no quieres ver en tu obra de arte aquí.
- Create Style: Si deseas guardar una combinación particular de promociones positivas y negativas como un 'estilo' para uso futuro, haz clic aquí.
- App Style: Implementa un estilo previamente guardado en tu prompt actual.
- Generate: Una vez que hayas configurado todos los parámetros, haz clic aquí para dar vida a tu imagen.
- Sampling Steps: Este parámetro define los pasos tomados para transformar el ruido aleatorio en tu imagen final. Un rango entre 20 y 75 generalmente produce buenos resultados, siendo 25-50 un punto intermedio práctico.
- Sampling Method: Si los Modelos representan el corazón de este programa, un muestreador es el cerebro detrás de todo. Esta es la técnica utilizada para tomar tus indicaciones, tus codificadores y cada parámetro, y convertir el ruido en una imagen coherente según tus órdenes. Hay muchos muestreadores, pero recomendamos "DDIM" para renders rápidos con pocos pasos, "Euler a" para dibujos o fotos de personas con piel suave, y "DPM" para imágenes detalladas (DPM++ 2M Karras probablemente sea una buena apuesta segura). Aquí tienes una recopilación de los resultados obtenidos con los diferentes métodos de muestreo o samplers para Stable Diffusion.
- Batch Count: La cantidad de lotes ejecutará múltiples imagenes de generaciones, una tras otra. Esto te permitirá crear diferentes imágenes con el mismo prompt. Aunque lleva más tiempo, utiliza menos vRAM porque cada imagen se genera después de que se haya completado la anterior
- Batch Size: Esto es cuántas imágenes paralelas en cada lote. Esto te dará más imágenes, más rápidamente, pero también utilizará más vRAM para procesar porque genera cualquier imagen en la misma generación.
- CFG Scale: Determina la libertad creativa del modelo, encontrando un equilibrio entre seguir tu indicación y su propia imaginación. Un CFG bajo hará que el modelo ignore tu indicación y sea más creativo, un CFG alto hará que se adhiera a ella sin ninguna libertad. Un valor entre 5 y 12 es típicamente seguro, con 7.5 proporcionando un punto intermedio confiable.
- Width and Height: Especifique aquí el tamaño de su imagen. Las resoluciones iniciales podrían ser 512X512, 512X768, 768x512 o 768x768. Para SDXL (el último modelo de Stability AI), la resolución base es de 1024x1024
- Seed: Piense en esto como el ID único de una imagen, estableciendo una referencia para el ruido aleatorio inicial. Es crucial si desea replicar un resultado específico. Además, cada imagen tiene una semilla única, por lo que es imposible replicar al 100% una imagen específica de la vida real, porque no tienen una semilla.
- El Icono de Dado: Establece la semilla en -1, aleatorizándola. Esto garantiza la singularidad para cada generación de imágenes.
- El Icono de Reciclaje: Mantiene la semilla de la última generación de imágenes.
- Script: Es la plataforma para ejecutar instrucciones avanzadas que afectan tu flujo de trabajo. Como principiante, es posible que desees dejar esto sin modificar por ahora.
- Save: Guarda tu imagen generada en una carpeta de tu elección. Ten en cuenta que Stable Diffusion también guarda automáticamente tus imágenes en su carpeta dedicada 'output'.
- Send to img2img: Envía tu resultado a la pestaña img2img, permitiendo que sea la referencia para nuevas generaciones que se le asemejen.
- Send to inpaint: Dirige tu imagen a la pestaña inpaint, lo que te permite modificar áreas específicas de la imagen, como los ojos, las manos o los artefactos.
- Send to extras: Esta acción traslada tu imagen a la pestaña 'extras', donde puedes cambiar el tamaño de tu imagen sin una pérdida significativa de detalles.
¡Eso es todo, estás listo! Ahora, deja que tu creatividad fluya y observa cómo se despliega la magia de Stable Diffusion.
Ingeniería de Prompt 101: Cómo crear buenos prompts para SD v1.5
El éxito de una aventura con Stable Diffusion depende en gran medida de tus prompts o instrucciones, piensa en ella como una brújula que guía a la IA. Cuantos más detalles, más precisa será la generación de imágenes.
A veces, la creación de prompts puede parecer desalentadora, ya que Stable Diffusion no sigue un patrón lineal. Es un proceso lleno de ensayo y error. Comienza con un prompt, genera imágenes, selecciona tu resultado preferido, modifica los elementos que aprecias o deseas eliminar, y luego comienza de nuevo. Repite este proceso hasta que tu obra maestra emerja de los ajustes de relleno y las mejoras implacables.
Instrucciones o "Prompts" positivos, negativos y ajuste del peso de las palabras clave
Antes que todo, es importante saber que Stable Diffusion entiende únicamente inglés, por lo que es importante que lo que le digamos sea en ese idioma. Una buena idea para comenzar es escribir el prompt en español, y luego pasarlo por algún traductor como Deepl, Google Translate, ChatGPT o Bard. De esta manera obtendrás las palabras adecuadas para poder usar tu modelo
El diseño de Stable Diffusion permite ajustar el peso de las palabras clave con la sintaxis (palabra clave:factor). Un factor por debajo de 1 reduce su importancia, mientras que valores por encima de 1 la amplifican. Para manipular el peso, selecciona la palabra clave específica y presiona Ctrl+Flecha Arriba para aumentar o Ctrl+Flecha Abajo para disminuir. Además, puedes utilizar paréntesis: cuanto más utilices, mayor será el peso de la palabra clave.
Los modificadores añaden ese toque final a tu imagen, especificando elementos como el estado de ánimo, el estilo o detalles como "oscuro, intrincado, altamente detallado, enfoque nítido".
Los prompts positivos describen los elementos deseados. Una estrategia confiable para la construcción de indicaciones es especificar el tipo de imagen, sujeto, medio, estilo, escenario, artista, herramientas utilizadas y resolución, en ese orden. Una demostración de civitai.com podría ser "“photorealistic render, (digital painting),(best quality), serene Japanese garden, cherry blossoms in full bloom, (((koi pond))), footbridge, pagoda, Ukiyo-e art style, Hokusai inspiration, Deviant Art popular, 8k ultra-realistic, pastel color scheme, soft lighting, golden hour, tranquil atmosphere, landscape orientation.”
En español dicho prompt equivaldría a algo como: "renderizado fotorrealista, (pintura digital), (mejor calidad), sereno jardín japonés, cerezos en plena floración, (((estanque de carpas))), puente peatonal, pagoda, estilo de arte Ukiyo-e, inspiración de Hokusai, popular en Deviant Art, ultra realista en 8k, esquema de colores pastel, iluminación suave, hora dorada, atmósfera tranquila, orientación horizontal".
Por el contrario, los prompts negativos detallan todo lo que deseas excluir de la imagen. Ejemplos incluyen: "dull colors, ugly, bad hands, too many fingers, NSFW, fused limbs, worst quality, low quality, blurry, watermark, text, low resolution, long neck, out of frame, extra fingers, mutated hands, monochrome, ugly, duplicate, morbid, bad anatomy, bad proportions, disfigured, low resolution, deformed hands, deformed feet, deformed face, deformed body parts, ((same haircut))." No tengas miedo de describir lo mismo con diferentes palabras.
Por cierto, la traducción del prompt anterior es algo similar a: "colores aburridos, feo, manos malas, demasiados dedos, NSFW, extremidades fusionadas, peor calidad, baja calidad, borroso, marca de agua, texto, baja resolución, cuello largo, fuera de cuadro, dedos extra, manos mutadas, monocromo, feo, duplicado, mórbido, anatomía incorrecta, proporciones incorrectas, desfigurado, baja resolución, manos deformadas, pies deformados, cara deformada, partes del cuerpo deformadas, (mismo corte de pelo)"
Una buena manera de pensar en una indicación es la estructura "Qué+SVCM (Sujeto, Verbo, Contexto, Modificador)":
- Qué: Identifica lo que deseas: Retrato, Foto, Ilustración, Dibujo, etc.
- Sujeto: Describe el tema en el que estás pensando: una mujer hermosa, un superhéroe, una persona asiática mayor, un soldado negro, niños pequeños, un paisaje hermoso.
- Verbo: Describe lo que está haciendo el sujeto: ¿La mujer está posando para la cámara? ¿El superhéroe está volando o corriendo? ¿La persona asiática está sonriendo o saltando?
- Contexto: Describe el escenario de tu idea: ¿Dónde está ocurriendo la escena? ¿En un parque, en un salón de clases, en una ciudad concurrida? Sé lo más descriptivo posible.
- Modificadores: añaden información adicional sobre tu imagen: si es una foto, qué lente se utilizó. Si es una pintura, qué artista la pintó. ¿Qué tipo de iluminación se utilizó, en qué sitio se presentaría? ¿Qué tipo de ropa o estilo de moda estás pensando, la imagen da miedo? Estos conceptos se separan por comas. Pero recuerda, cuanto más cerca estén del principio, más prominentes serán en la composición final. Si no sabes por dónde empezar, este sitio y este repositorio de Github tienen muchas buenas ideas para que experimentes si no quieres simplemente copiar/pegar las ideas de otras personas
Entonces, un ejemplo de una indicación positiva podría ser: Portrait of a cute poodle dog posing for the camera in an expensive hotel, (((black tail))), fall, bokeh, Masterpiece, hard light, film grain, Canon 5d mark 4, F/1.8, Agfacolor, unreal engine.
Traducción: Retrato de un lindo perro posando para la cámara en un hotel de lujo, (((cola negra))), otoño, bokeh, obra maestra, luz dura, grano de película, Canon 5d mark 4, F/1.8, Agfacolor, motor irreal.
Las indicaciones negativas o prompts negativos no necesitan una estructura adecuada, simplemente agrega todo lo que no te gusta, como si fueran modificadores. Si generas una imagen y ves algo que no te gusta, simplemente agrégalo a tu indicación negativa, vuelve a ejecutar la generación y evalúa los resultados. Así es como funciona la generación de imágenes con IA, no es un milagro. Ejemplos de prompts negativos son: borroso, mal dibujado, gato, humanos, persona, boceto, horror, feo, mórbido, deformado, logotipo, texto, mala anatomía, malas proporciones, etc.
Integración de palabras clave y programación de indicaciones
La mezcla de palabras clave o la programación de indicaciones emplea la sintaxis [palabra clave1: palabra clave2: factor]. El factor, un número entre 0 y 1, determina en qué paso la palabra clave1 cambia a la palabra clave2.
La forma fácil: copiar indicaciones
Si no estás seguro por dónde empezar, considera aprovechar ideas de varios sitios web y adaptarlas a tus necesidades. Excelentes fuentes de indicaciones incluyen:
Alternativamente, guarda una imagen generada por IA que admires, arrástrala y suéltala en la pestaña "PNG Info", y Stable Diffusion proporcionará la indicación e información relevante para recrearla. Si la imagen no es generada por IA, considera usar el complemento CLIP Interrogator para obtener una mejor comprensión de su descripción. Se proporcionan más detalles sobre este complemento más adelante en la guía.
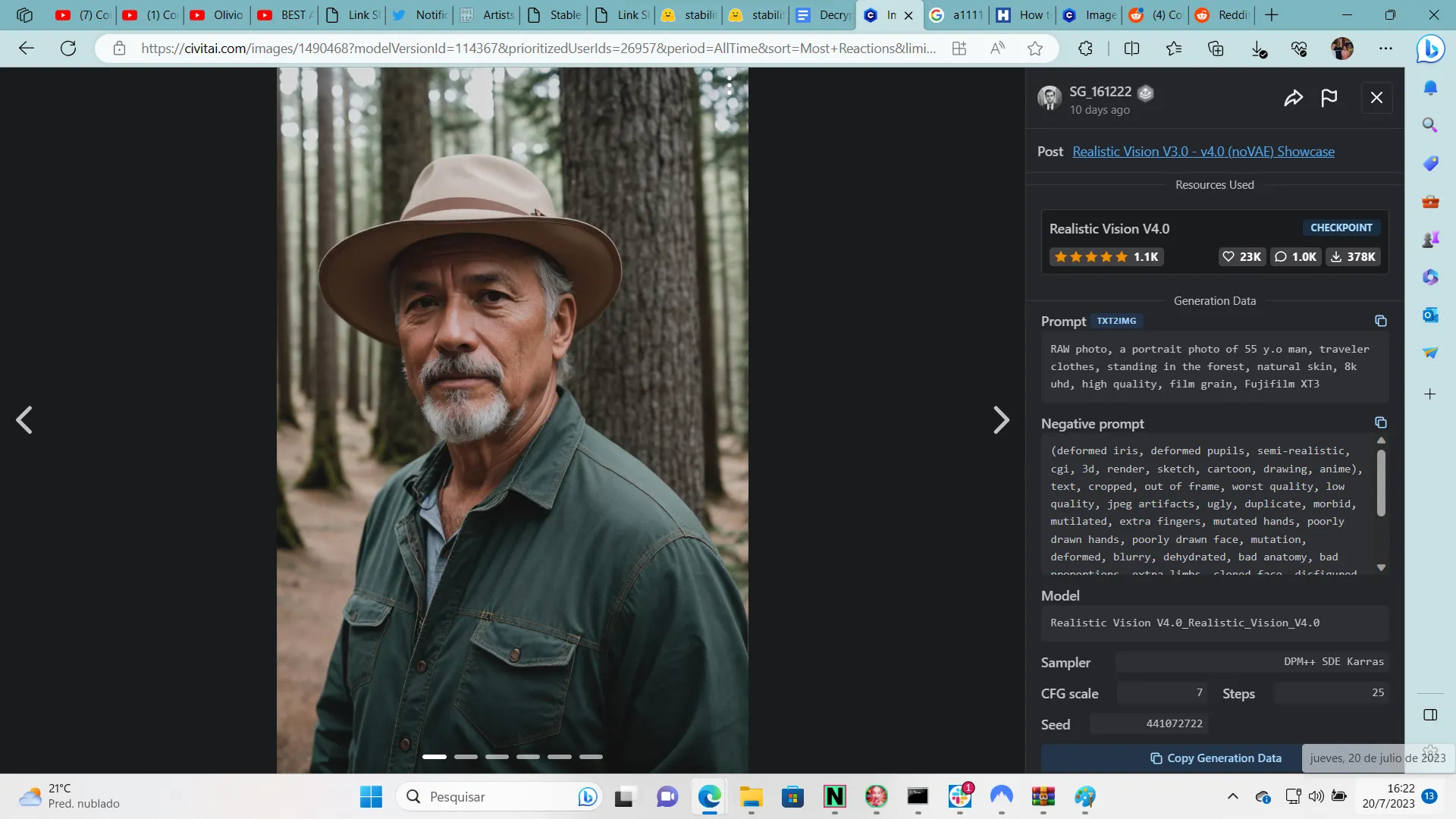
Evitando obstáculos
Stable Diffusion es tan buena como los prompts que se le dan. Basándose en el detalle y la precisión, es esencial proporcionar indicaciones claras y específicas y favorecer los conceptos en lugar de las explicaciones. En lugar de usar una oración elaborada para describir una escena espaciosa y naturalmente iluminada, simplemente escribe "spacious, natural light" que equivaldría a "espaciosa, luz natural".
Ten en cuenta las asociaciones no deseadas que ciertos atributos pueden generar, como etnias específicas al especificar el color de ojos. Estar alerta a estos posibles obstáculos puede ayudarlo a crear indicaciones más efectivas.
Recuerda, cuanto más específicas sean tus instrucciones, más controlado será el resultado. Sin embargo, ten cuidado si pretendes crear instrucciones largas, porque el uso de palabras clave contradictorias (por ejemplo, cabello largo y luego cabello corto, o "borroso" en el prompt negativo y "desenfocado" en el prompt positivo) podría llevar a resultados inesperados:
Instalación de nuevos modelos
La instalación de modelos es un proceso sencillo. Comienza por identificar un modelo adecuado a tus necesidades. Un buen punto de partida es Civitai, conocido por ser el repositorio más grande de herramientas de Stable Diffusion. A diferencia de otras alternativas, Civitai fomenta que la comunidad comparta sus experiencias, proporcionando referencias visuales sobre las capacidades de un modelo.
Visita Civitai, haz clic en el ícono de filtro y selecciona "Checkpoints" en la sección "model types".
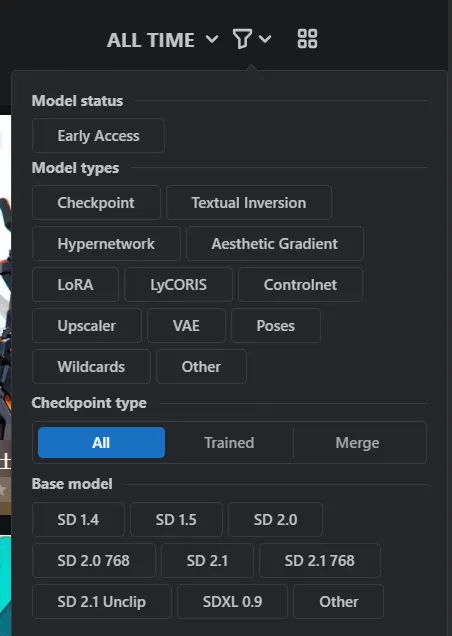
Luego, navega por todos los modelos disponibles en el sitio. Ten en cuenta que Stable Diffusion no tiene censura y es posible que encuentres contenido NSFW. Selecciona tu modelo preferido y haz clic en descargar. Asegúrate de que el modelo tenga una extensión .safetensor para mayor seguridad (los modelos antiguos usaban una extensión .ckpt que no es tan segura).
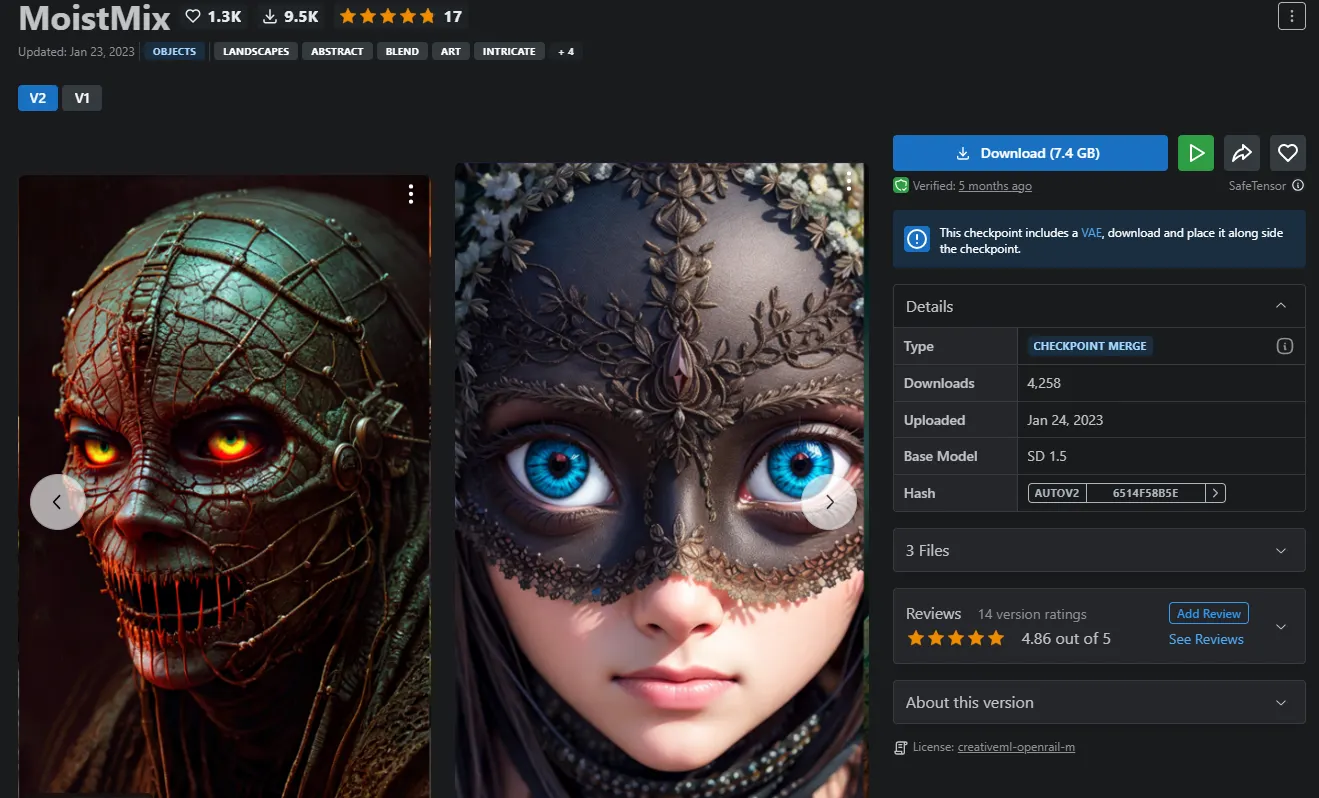
Una vez descargado, coloca el modelo en la carpeta de modelos locales de Automatic 1111. Para hacer esto, ve a la carpeta donde instalaste tu Stable Diffusion con A111 y sigue esta ruta: "stable-diffusion-webuimodelsStable-diffusion"
Hay cientos de modelos para elegir, pero como referencia, algunos de nuestros favoritos son:
- Juggernaut, Photon, Realistic Vision y aZovya Photoreal si quieres jugar con imágenes fotorrealistas.
- Dreamshaper, RevAnimated y todos los modelos de DucHaiten si te gusta el arte en 3D.
- DuelComicMix, DucHaitenAnime, iCoMix, DucHaitenAnime si te gusta el arte en 2D como mangas y cómics.
Edición de tu imagen: de Image to Image e Inpaint
Stable Diffusion también te permite usar IA para editar imágenes que no te gusten. Es posible que desees cambiar el estilo artístico de tu composición, agregar pájaros al cielo, eliminar artefactos o modificar una mano con demasiados dedos. Para esto, existen dos técnicas: de imagen a imagen y de relleno.
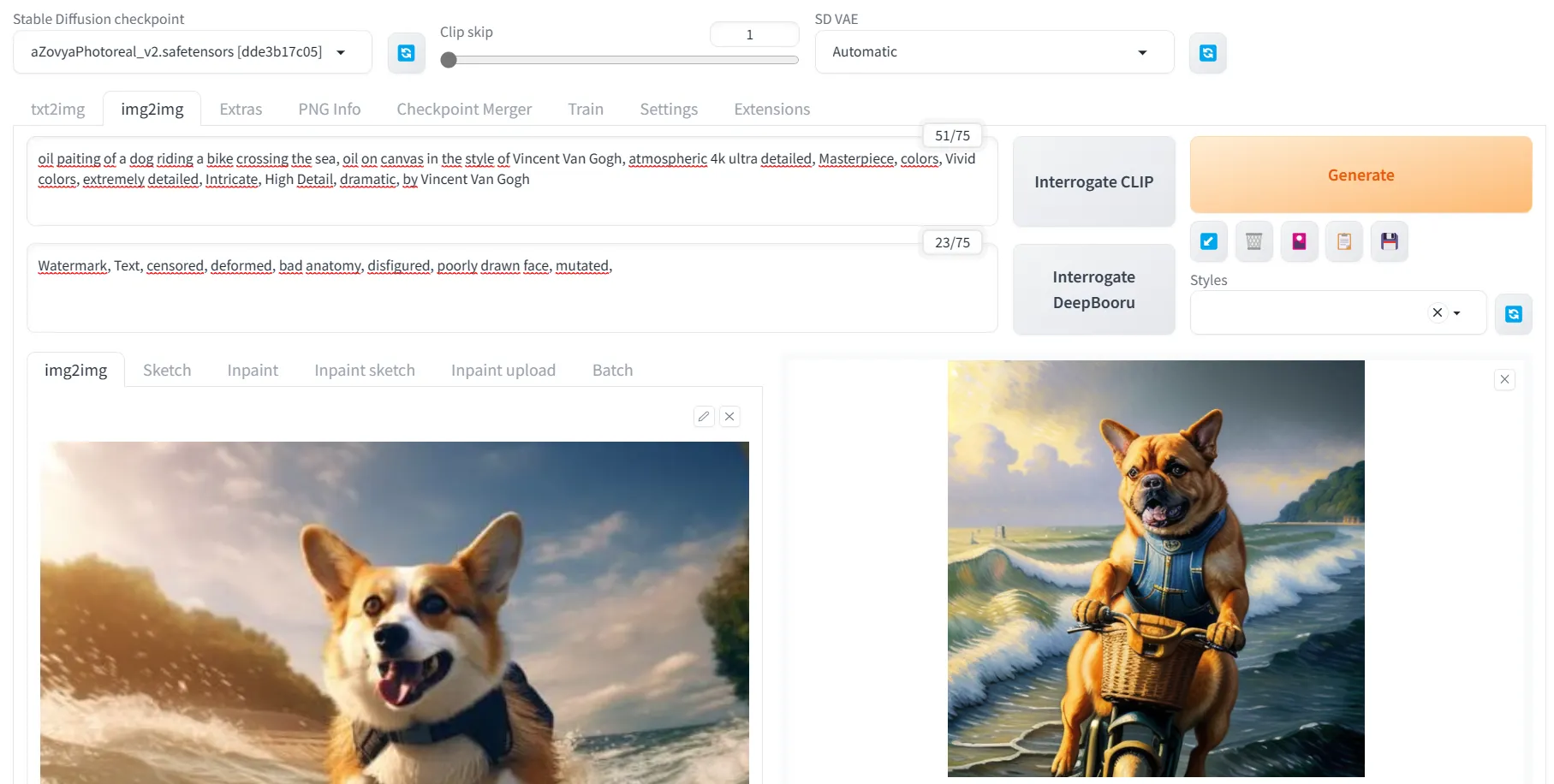
Image to Image o imagen -a-imagen básicamente permite que Stable Diffusion cree una nueva imagen utilizando otra imagen como referencia, no importa si es una imagen real o una que hayas creado. Para hacer esto, simplemente haz clic en la pestaña Image to Image (Img2Img), coloca la imagen de referencia en el cuadro correspondiente, crea la indicación que deseas que siga la máquina y haz clic en generar. Es importante tener en cuenta que cuanto más fuerza de eliminación de ruido o denoising strength apliques, menos se parecerá la nueva imagen a la original porque Stable Diffusion tendrá más libertad creativa.
Sabiendo esto, puedes hacer algunos trucos interesantes, como escanear esas viejas fotos de tus abuelos como referencia, pasarlas por Stable Diffusion con una baja fuerza de eliminación de ruido y una indicación muy general como "imagen RAW, 4k, altamente detallada" y ver cómo la IA reconstruye tu foto.
El Inpainting te permite pintar o editar cosas dentro de la imagen original. Para eso, desde la misma pestaña Img2Img, selecciona la opción de relleno y coloca tu pintura de referencia allí.
Luego, simplemente pintas el área que deseas editar (por ejemplo, el cabello de tu personaje) y agregas la indicación que deseas crear (por ejemplo, cabello largo y rubio liso), ¡y listo!
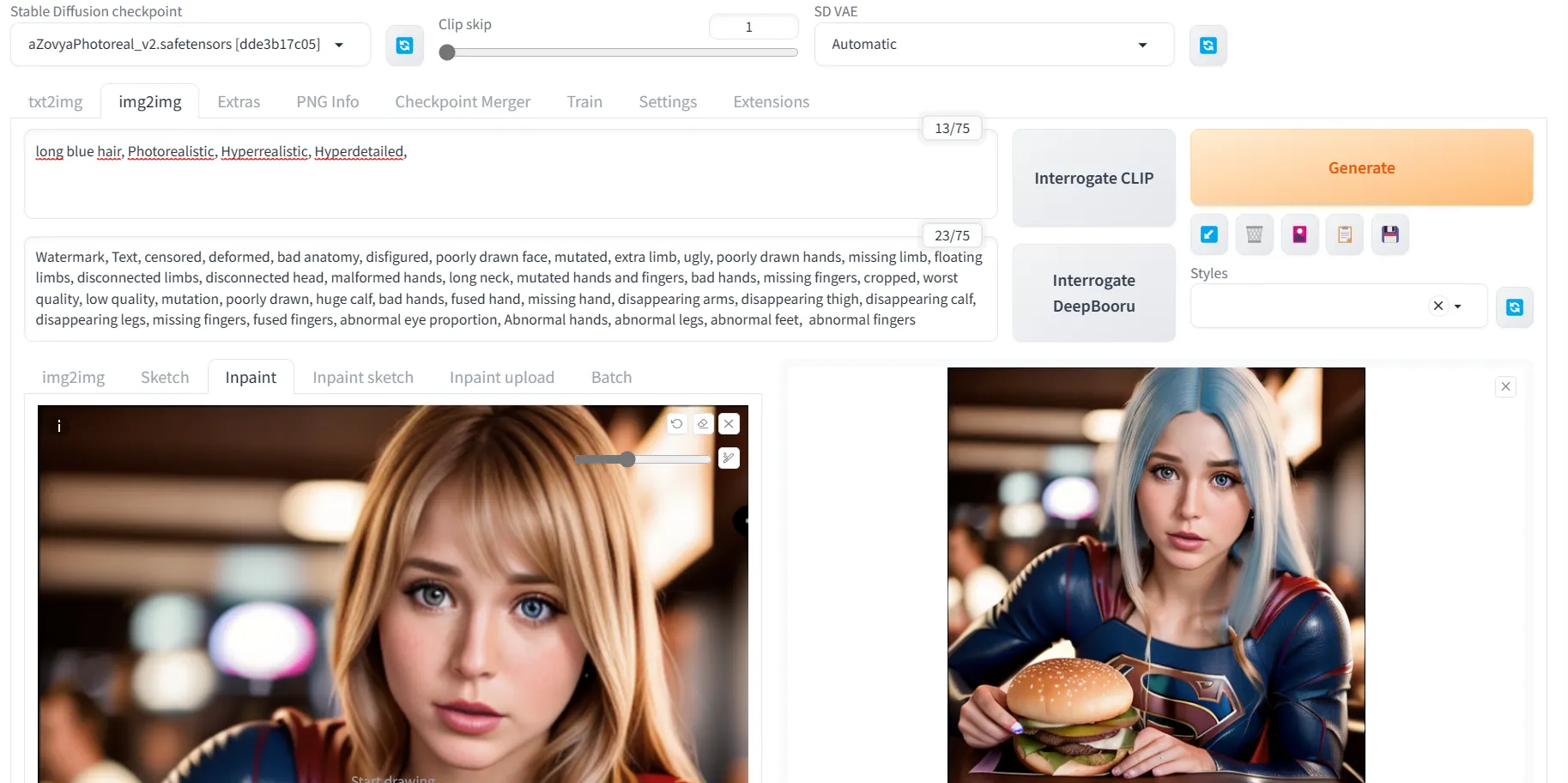
Recomendamos generar varias series de imágenes para que puedas elegir la que más te guste y modificar tu indicación. Sin embargo, al final, siempre es bueno tener una herramienta como Photoshop a mano para obtener resultados perfectos si eres muy meticuloso.
Las 5 mejores extensiones para mejorar las capacidades de Stable Diffusion
Ahora que estás familiarizado con Stable Diffusion, es posible que estés ansioso por llevar tu creatividad aún más lejos. Tal vez quieras corregir una posición específica de la mano, obligar al modelo a generar una mano de cinco dedos, especificar un tipo de vestido determinado, mejorar detalles, usar un rostro en particular o transformar tu imagen pequeña en un archivo masivo de 8K con una pérdida mínima de detalles.
Las extensiones pueden ayudarte a lograr estos objetivos. Si bien hay numerosas opciones disponibles, hemos destacado cinco que podrían ser imprescindibles:
LoRAs: Porque el diablo está en los detalles

Las LoRAs son archivos diseñados para mejorar la especificidad de tu modelo sin descargar un modelo completamente nuevo. Esto te permite refinar detalles, emplear un rostro, vestimenta o estilo específico.
Para instalar una LoRA, sigue estos pasos:
- Haz clic en la pestaña de Extensiones y selecciona "Instalar desde URL".
- Ingresa la URL: https://github.com/kohya-ss/sd-webui-additional-networks.git en el cuadro y haz clic en Instalar.
- Una vez completado, haz clic en "Instalado" y luego en "Aplicar y reiniciar la interfaz de usuario".
La instalación de un LoRA sigue los mismos pasos que la instalación de un modelo. En Civitai, establece el filtro en "LoRA" y coloca el archivo en la carpeta de los LoRA utilizando esta ruta: stable-diffusion-webui/models/Lora
Recuerda, algunos LoRAs requieren una palabra clave específica en tu indicación para activarse, así que asegúrate de leer su descripción antes de usarlas.
Para usar un LoRA, ve a la pestaña de texto a imagen, haz clic en el icono que se asemeja a una pequeña pintura (Mostrar/ocultar redes adicionales) y los LoRAs aparecerán debajo de tu indicación.
ControlNet: Desatando el Poder de la Magia Visual

Si estás indeciso acerca de las capacidades de Stable Diffusion, deja que la extensión ControlNet sea la respuesta definitiva. Con una versatilidad y potencia inmensas, ControlNet te permite extraer composiciones de imágenes de referencia, demostrándose como un cambio de juego en la generación de imágenes.
ControlNet es verdaderamente un todoterreno. Ya sea que necesites replicar una pose, emular una paleta de colores, rediseñar tu espacio de vida, crear manos de cinco dedos, realizar un escalado virtualmente ilimitado sin sobrecargar tu GPU o convertir simples garabatos en impresionantes representaciones en 3D o imágenes fotorrealistas, ControlNet allana el camino.
La instalación de ControlNet implica estos sencillos pasos:
- Visita la página de la extensión y selecciona la pestaña 'Instalar desde URL'.
- Pega la siguiente URL en el campo 'URL del repositorio de la extensión': https://github.com/Mikubill/sd-webui-controlnet
- Haz clic en 'Instalar'.
- Cierra tu interfaz de Stable Diffusion.
Para habilitar ControlNet, deberás descargar los modelos de este repositorio: https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
Luego, copia todos los archivos descargados en esta carpeta: stable-diffusion-webuiextensionssd-webui-controlnetmodels
Al reiniciar Stable Diffusion, notarás una nueva sección llamada 'ControlNet' en la pestaña de texto a imagen.
Se te presentarann dos opciones principales: un cuadro para arrastrar/soltar tu imagen de referencia, selección de tipo de control y el preprocesador.
- El cuadro 'Imagen de referencia' es donde cargas la imagen que deseas utilizar como referencia para la pose, el rostro, la composición de color, la estructura, etc.
- La 'Selección del tipo de control' es donde ocurre la magia de ControlNet. Esta función te permite determinar qué quieres copiar o controlar.
Tienes otras opciones más avanzadas que te permiten afinar los resultados: Preprocesadores (técnica utilizada para activar el controlnet), Pesos (qué tan importante es tu referencia) y puntos de inicio/fin (cuándo comenzará/terminará la influencia del controlnet)
Aquí tienes una descripción general de lo que logra cada tipo de control:
- OpenPose: Localiza las partes clave del cuerpo y replica una pose. Puedes seleccionar una pose para todo el cuerpo, la cara o las manos utilizando el preprocesador.
- Canny: Convierte tu imagen de referencia en un garabato en blanco y negro con líneas finas. Esto permite que tus creaciones sigan estas líneas como bordes, lo que resulta en un parecido preciso a tu referencia.
- Depth: Genera un 'mapa de profundidad' para crear una impresión en 3D de la imagen, distinguiendo objetos cercanos y lejanos, ideal para imitar tomas y escenas cinematográficas en 3D.
- Normal: Un mapa normal infiere la orientación de una superficie, excelente para texturizar objetos como armaduras, telas y estructuras exteriores.
- MLSD: Reconoce líneas rectas, lo que lo hace ideal para reproducir diseños arquitectónicos.
- Lineart: Transforma una imagen en un dibujo, útil para imágenes en 2D como anime y dibujos animados.
- Soft Edges: Similar a un modelo Canny pero con bordes más suaves, ofrece más libertad al modelo y ligeramente menos precisión.
- Scribble: Convierte una imagen en un garabato, obteniendo resultados más generalizados que el modelo Canny. Además, puedes crear un garabato en paint y usarlo como referencia sin un preprocesador para convertir tus imágenes en creaciones realistas.
- Segmentación: Crea un mapa de colores de tu imagen, inferiendo los objetos dentro de ella. Cada color representa un tipo específico de objeto. Puedes usarlo para redecorar tu imagen o reimaginar una escena con el mismo concepto (por ejemplo, convertir una foto de 1800 en una representación fotorrealista de la misma escena en una realidad alternativa de cyberpunk o simplemente redecorar tu habitación con una cama diferente, paredes de un color diferente, etc.)
- Tile: Agrega detalles a la imagen y facilita el aumento de escala sin sobrecargar tu GPU.
- Inpaint: Modifica la imagen o amplía sus detalles. Ahora, gracias a la actualización reciente y al modelo "impaint only + llama", puedes pintar imágenes con una atención extrema al detalle
- Shuffle: Reproduce la estructura de color de una imagen de referencia.
- Reference: Genera imágenes similares a tu referencia en estilo, composición y ocasionalmente rostros.
- T2IA: Te permite controlar el color y la composición artística de tu imagen.
Dominar estas opciones puede llevar tiempo, pero la flexibilidad y personalización que ofrecen valen la pena el esfuerzo. Consulta varios tutoriales y videos instructivos en línea para aprovechar al máximo ControlNet.
Roop: Deepfakes al alcance de tus dedos

Roop proporciona un método sin complicaciones para generar deepfakes realistas. En lugar de trabajar con modelos complejos o LoRAs, Roop se encarga de la parte pesada, lo que te permite crear deepfakes de alta calidad con unos pocos clics simples.
Para descargar y activar, sigue las instrucciones disponibles en el repositorio oficial de Roop en Github
Para usarlo, crea una prompt, navega hasta el menú de Roop, carga una cara de referencia, habilítala y genera tu imagen. La extensión se encargará de cambiar automáticamente el rostro generado por el que le hayas dado como referencia. Para obtener los mejores resultados, utiliza una toma frontal de alta resolución de la cara que deseas replicar. Recuerda que diferentes imágenes de la misma persona pueden producir resultados diferentes, algunos más realistas que otros.
Photopea: El poder de Photoshop dentro de Stable Diffusion
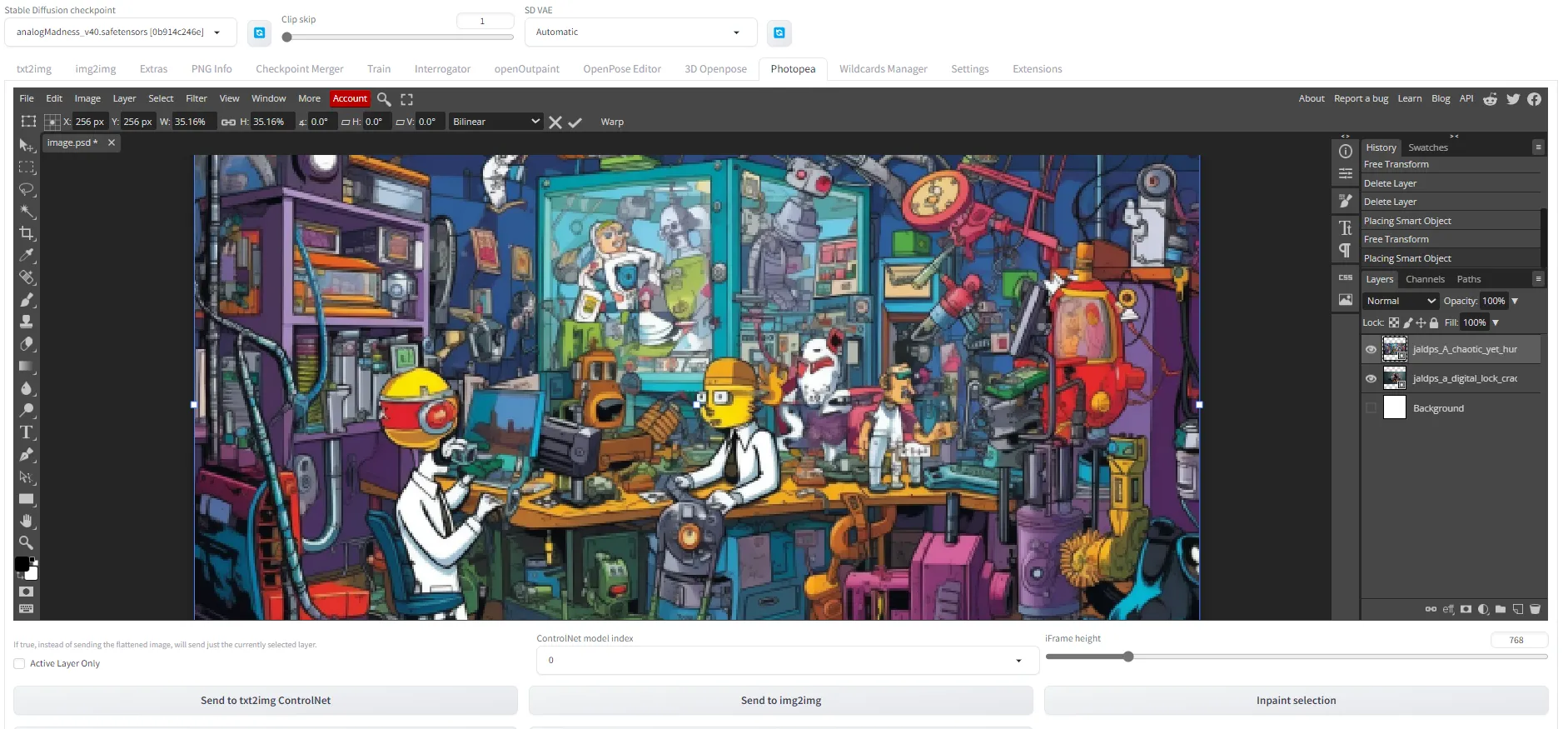
A veces, se necesitan ajustes manuales para lograr el resultado perfecto, y ahí es donde entra Photopea. Esta extensión trae funcionalidades similares a Photoshop directamente a la interfaz de Stable Diffusion, lo que te permite ajustar tus imágenes generadas sin cambiar de plataforma.
Puedes instalar Photopea desde este repositorio: https://github.com/yankooliveira/sd-webui-photopea-embed
CLIP Interrogator: Creando indicaciones a partir de cualquier imagen
Esta es una gran herramienta si no sabes por dónde empezar con las sugerencias. Toma una imagen, pégala en el cuadro, ejecuta el interrogador y te dirá qué palabras se pueden asociar con la imagen que proporcionaste.
El Interrogador CLIP es una herramienta útil para obtener palabras clave de una imagen específica. Al combinar CLIP de OpenAI y BLIP de Salesforce, esta extensión genera sugerencias de texto que coinciden con una imagen de referencia dada.
Puedes instalarlo desde este repositorio: https://github.com/pharmapsychotic/clip-interrogator-ext.git
Conclusión
Con Stable Diffusion, te conviertes en el maestro de tu orquesta visual. Ya sea un "retrato hiperrealista de Emma Watson como hechicera" o una "pintura digital detallada de un pirata en un entorno de fantasía", el único límite es tu imaginación.
Ahora, armado con tu nuevo conocimiento, ve y convierte tus sueños en realidad, una indicación de texto a la vez.

Imagen creada por Decrypt usando IA/Jose Lanz
