

En Resumen
- LM Studio ofrece una interfaz gráfica intuitiva para ejecutar modelos de IA localmente, mientras que Ollama se dirige a desarrolladores avanzados mediante línea de comandos con mayor flexibilidad y automatización.
- Los modelos de 7-9 mil millones de parámetros con cuantificación de 4 bits funcionan cómodamente en sistemas con 8GB de VRAM, permitiendo ejecutar IA local sin conexión y sin costos de suscripción.
- DeepSeek y Qwen destacan como opciones recomendadas para comenzar, con Nemotron liderando en codificación y Mistral 7B sobresaliendo en chatbots y juegos de rol según las pruebas.
Si no eres un desarrollador, ¿por qué diablos querrías ejecutar un modelo de IA de código abierto en tu computadora de casa?
Resulta que hay muchas razones. Y con modelos gratuitos y de código abierto cada vez mejores, y fáciles de usar, con requisitos de hardware mínimos, ahora es un buen momento para probarlo.
Aquí tienes algunas razones por las que los modelos de código abierto son mejores que pagar $20 al mes a ChatGPT, Perplexity o Google:
- Es gratis. Sin cuotas de suscripción.
- Tus datos permanecen en tu máquina.
- Funciona sin conexión, no se requiere internet.
- Puedes entrenar y personalizar tu modelo para casos de uso específicos, como escritura creativa o... bueno, cualquier cosa.
La barrera de entrada se ha derrumbado. Ahora existen programas especializados que permiten a los usuarios experimentar con la inteligencia artificial sin la molestia de instalar bibliotecas, dependencias y complementos de forma independiente. Casi cualquier persona con una computadora bastante reciente puede hacerlo: una computadora portátil o de escritorio de gama media con 8GB de memoria de video puede ejecutar modelos sorprendentemente capaces, y algunos modelos funcionan con 6GB o incluso 4GB de VRAM. Y para Apple, cualquier chip de la serie M (de los últimos años) podrá ejecutar modelos optimizados.
El software es gratuito, la configuración lleva minutos y el paso más intimidante, elegir qué herramienta usar, se reduce a una pregunta simple: ¿Prefieres hacer clic en botones o escribir comandos?
LM Studio vs. Ollama
Dos plataformas dominan el espacio local de IA, y abordan el problema desde ángulos opuestos.
LM Studio envuelve todo en una interfaz gráfica pulida. Simplemente puedes descargar la aplicación, explorar una biblioteca de modelos integrada, hacer clic para instalar y comenzar a chatear. La experiencia es similar a usar ChatGPT, excepto que el procesamiento se realiza en tu hardware. Los usuarios de Windows, Mac y Linux obtienen la misma experiencia fluida. Para los recién llegados, este es el punto de partida obvio.
Ollama está dirigido a desarrolladores y usuarios avanzados que trabajan en la terminal. Se instala a través de la línea de comandos, se descargan modelos con un solo comando y luego se scriptea o automatiza según tu contenido. Es ligero, rápido e se integra perfectamente en los flujos de trabajo de programación.
La curva de aprendizaje es más pronunciada, pero la recompensa es la flexibilidad. También es lo que eligen los usuarios avanzados por su versatilidad y personalización.
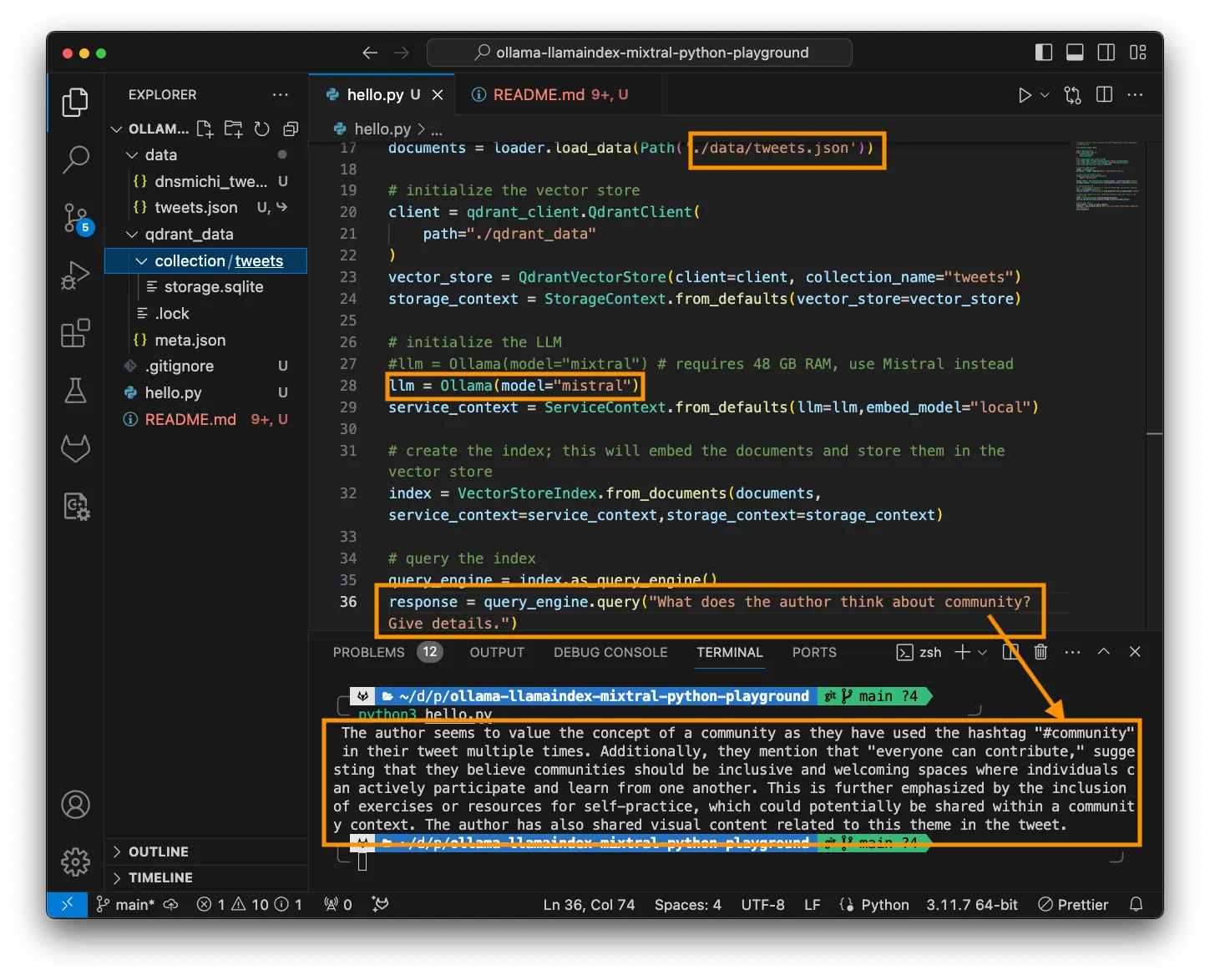
Ambas herramientas ejecutan los mismos modelos subyacentes utilizando motores de optimización idénticos. Las diferencias de rendimiento son insignificantes.
Configuración de LM Studio
Visita https://lmstudio.ai/ y descarga el instalador para tu sistema operativo. El archivo pesa alrededor de 540MB. Ejecuta el instalador y sigue las indicaciones. Inicia la aplicación.
Pista 1: Si te pregunta qué tipo de usuario eres, elige "desarrollador". Los otros perfiles simplemente ocultan opciones para facilitar las cosas.
Pista 2: Recomendará descargar OSS, el modelo de IA de código abierto de OpenAI. En su lugar, haz clic en "omitir" por ahora; hay modelos mejores y más pequeños que harán un mejor trabajo.
VRAM: La clave para ejecutar IA local
Una vez que hayas instalado LM Studio, el programa estará listo para ejecutarse y se verá así:
Ahora necesitas descargar un modelo antes de que tu LLM funcione. Y cuanto más potente sea el modelo, más recursos requerirá.
El recurso crítico es la VRAM, o memoria de video en tu tarjeta gráfica. Los LLM se cargan en la VRAM durante la inferencia. Si no tienes suficiente espacio, el rendimiento se colapsa y el sistema debe recurrir a la RAM del sistema más lenta. Querrás evitar eso teniendo suficiente VRAM para el modelo que deseas ejecutar.
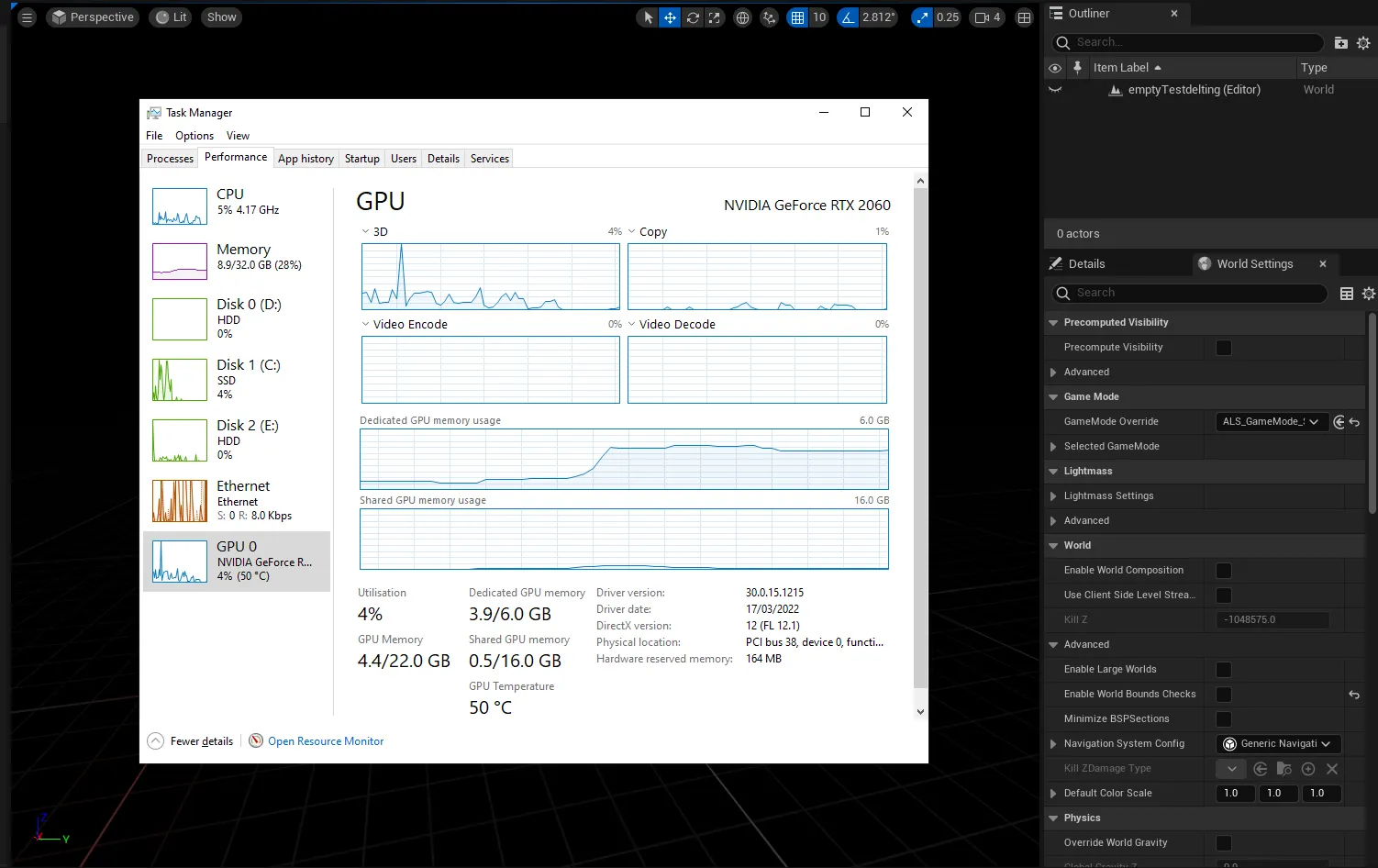
Para saber cuánta VRAM tienes, puedes ingresar al administrador de tareas de Windows (control+alt+del) y hacer clic en la pestaña de GPU, asegurándote de haber seleccionado la tarjeta gráfica dedicada y no la gráfica integrada en tu procesador Intel/AMD.
Verás cuánta VRAM tienes en la sección "Memoria de GPU dedicada".
En las Mac M-Series, las cosas son más fáciles ya que comparten RAM y VRAM. La cantidad de RAM en tu máquina será igual a la VRAM a la que puedes acceder.
Para verificar, haz clic en el logo de Apple, luego haz clic en "Acerca de". ¿Ves donde dice Memoria? Esa es la cantidad de VRAM que tienes.

Necesitarás al menos 8GB de VRAM. Los modelos en el rango de 7-9 mil millones de parámetros, comprimidos usando cuantificación de 4 bits, se ajustan cómodamente mientras ofrecen un rendimiento sólido. Sabrás si un modelo está cuantificado porque los desarrolladores generalmente lo revelan en el nombre. Si ves BF, FP o GGUF en el nombre, entonces estás viendo un modelo cuantificado. Cuanto menor sea el número (FP32, FP16, FP8, FP4), menos recursos consumirá.
No es una comparación directa, pero imagina la cuantificación como la resolución de tu pantalla. Verás la misma imagen en 8K, 4K, 1080p o 720p. Podrás captar todo sin importar la resolución, pero al hacer zoom y ser exigente con los detalles, descubrirás que una imagen 4K tiene más información que una de 720p, pero requerirá más memoria y recursos para renderizar.
Pero idealmente, si realmente te tomas en serio esto, entonces deberías comprar una buena GPU de juegos con 24GB de VRAM. No importa si es nueva o no, y no importa qué tan rápida o potente sea. En el mundo de la IA, la VRAM es la reina.
Una vez que sepas cuánta VRAM puedes utilizar, entonces puedes averiguar qué modelos puedes ejecutar yendo al Calculadora de VRAM. O simplemente comienza con modelos más pequeños de menos de 4 mil millones de parámetros y luego pasa a modelos más grandes hasta que tu computadora te diga que no tienes suficiente memoria. (Más sobre esta técnica en un momento.)
Descargando tus modelos
Una vez que conozcas los límites de tu hardware, es hora de descargar un modelo. Haz clic en el icono de la lupa en la barra lateral izquierda y busca el modelo por su nombre.
Qwen y DeepSeek son buenos modelos para comenzar tu viaje. Sí, son chinos, pero si te preocupa ser espiado, entonces puedes estar tranquilo. Cuando ejecutas tu LLM localmente, nada sale de tu máquina, por lo que no serás espiado ni por los chinos, ni por el gobierno de EE. UU., ni por ninguna entidad corporativa.
En cuanto a los virus, todo lo que estamos recomendando proviene de Hugging Face, donde el software se verifica al instante en busca de spyware y otros malware. Pero, por lo que vale, el mejor modelo estadounidense es el Llama de Meta, por lo que es posible que desees elegir ese si eres un patriota. (Ofrecemos otras recomendaciones en la sección final.)
Ten en cuenta que los modelos se comportan de manera diferente dependiendo del conjunto de datos de entrenamiento y las técnicas de ajuste fino utilizadas para construirlos. A pesar de lo que diga Grok de Elon Musk, no existe tal cosa como un modelo imparcial porque no existe tal cosa como información imparcial. Así que elige tu veneno dependiendo de cuánto te importen la geopolítica.
Por ahora, descarga tanto las versiones 3B (modelo más pequeño y menos capaz) como las 7B. Si puedes ejecutar la versión 7B, entonces elimina la 3B (y prueba descargar y ejecutar la versión 13B y así sucesivamente). Si no puedes ejecutar la versión 7B, entonces elimínala y utiliza la versión 3B.
Una vez descargado, carga el modelo desde la sección Mis Modelos. Aparece la interfaz de chat. Escribe un mensaje. El modelo responde. ¡Felicidades: estás ejecutando una IA local!
Dando acceso a internet a tu modelo
De fábrica, los modelos locales no pueden navegar por la web. Están aislados por diseño, por lo que interactuarás con ellos basándote en su conocimiento interno. Funcionarán bien para escribir historias cortas, responder preguntas, hacer algo de programación, etc. Pero no te darán las últimas noticias, no te dirán el clima, no revisarán tu correo electrónico ni programarán reuniones por ti.
Los servidores del Protocolo de Contexto del Modelo cambian esto.
MCP servers actúan como puentes entre tu modelo y servicios externos. ¿Quieres que tu IA busque en Google, revise repositorios de GitHub o lea sitios web? Las MCP servers lo hacen posible. LM Studio agregó soporte para MCP en la versión 0.3.17, accesible a través de la pestaña Programa. Cada servidor expone herramientas específicas: búsqueda web, acceso a archivos, llamadas a API.
Si deseas darle a los modelos acceso a internet, entonces nuestra guía completa de MCP servers te guiará a través del proceso de configuración, incluyendo opciones populares como búsqueda web y acceso a bases de datos.
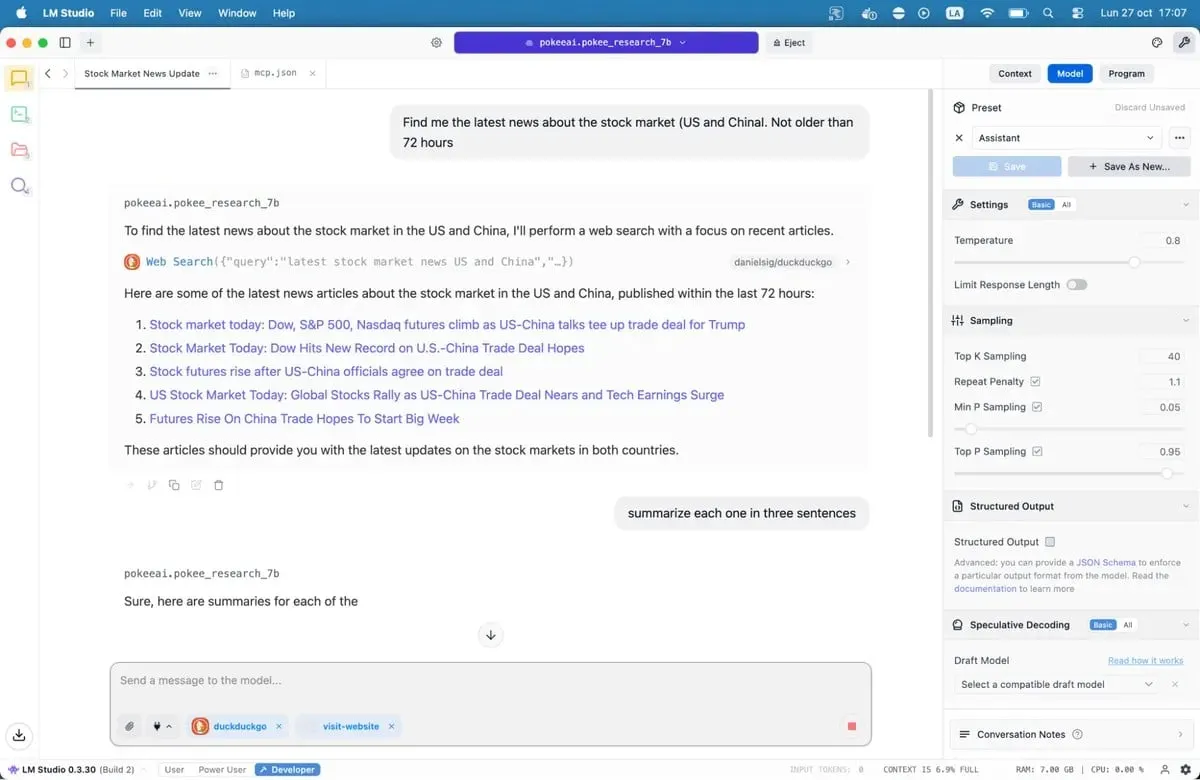
Guarda el archivo y LM Studio cargará automáticamente los servidores. Cuando chatees con tu modelo, ahora podrá llamar a estas herramientas para obtener datos en tiempo real. Tu IA local acaba de adquirir superpoderes.
Nuestros modelos recomendados para sistemas de 8GB
Literalmente hay cientos de LLMs disponibles para ti, desde opciones versátiles hasta modelos especializados diseñados para casos de uso específicos como programación, medicina, juegos de rol o escritura creativa.
Mejor para codificación: Nemotron o DeepSeek son buenos. No te volarán la cabeza, pero funcionarán bien con la generación de código y la depuración, superando a la mayoría de las alternativas en las pruebas de programación. DeepSeek-Coder-V2 6.7B ofrece otra opción sólida, especialmente para el desarrollo multilingüe.
Mejor para conocimiento general y razonamiento: Qwen3 8B. El modelo tiene fuertes capacidades matemáticas y maneja consultas complejas de manera efectiva. Su ventana de contexto acomoda documentos más largos sin perder coherencia.
Mejor para escritura creativa: Variantes de DeepSeek R1, pero necesitas algo de ingeniería de indicaciones pesadas. También hay ajustes finos sin censura como la versión "abliterated-uncensored-NEO-Imatrix" de GPT-OSS de OpenAI, que es buena para el horror; o Dirty-Muse-Writer, que es bueno para la erótica (según dicen).
Mejor para chatbots, juegos de rol, ficción interactiva, servicio al cliente: Mistral 7B (especialmente Undi95 DPO Mistral 7B) y variantes de Llama con grandes ventanas de contexto. MythoMax L2 13B mantiene rasgos de carácter a lo largo de conversaciones largas y adapta el tono de forma natural. Para otros juegos de rol NSFW, hay muchas opciones. Puede que quieras revisar algunos de los modelos en esta lista.
Para MCP: Jan-v1-4b y Pokee Research 7b son buenos modelos si quieres probar algo nuevo. DeepSeek R1 es otra buena opción.
Todos los modelos se pueden descargar directamente desde LM Studio si simplemente buscas por sus nombres.
Ten en cuenta que el panorama de LLM de código abierto está cambiando rápidamente. Semanalmente se lanzan nuevos modelos, cada uno afirmando mejoras. Puedes revisarlos en LM Studio, o navegar por los diferentes repositorios en Hugging Face. Prueba las opciones por ti mismo. Los malos ajustes se vuelven obvios rápidamente, gracias a frases incómodas, patrones repetitivos y errores factuales. Los buenos modelos se sienten diferentes. Razonan. Te sorprenden.
La tecnología funciona. El software está listo. Tu computadora probablemente ya tiene suficiente potencia. Lo único que queda es probarlo.