

En Resumen
- Alibaba lanzó Qwen 3.7 Max-Preview y Plus-Preview, ubicándose en el puesto 13 global de Text Arena y 7mo en matemáticas.
- Qwen 3.7 Max superó a Xiaomi MiMo en lógica, matemáticas y código, aunque mostró debilidades en razonamiento narrativo.
- El modelo Plus será código abierto, mientras Max permanecerá propietario; el lanzamiento oficial se esperaba tras el Cloud Summit del 20 de mayo.
Alibaba está lanzando modelos de IA a un ritmo vertiginoso, y ahora son más poderosos que nunca con la familia Qwen 3.7 disponible para pruebas. Esta semana, dos nuevos modelos aparecieron discretamente en el ranking de Arena AI: Qwen 3.7 Max-Preview y Qwen 3.7-Plus-Preview. Los modelos son, por supuesto, el aperitivo para el Alibaba Cloud Summit 2026.
🚀🚀Qwen3.7 Preview lands on Arena !
Here come Qwen3.7-Max-Preview & Qwen3.7-Plus-Preview. Alibaba now #6 lab in Text, #5 in Vision.⚡️⚡️
Can't wait to release Qwen3.7 series models!Stay tuned! @arena https://t.co/nhtxlCZI6D
— Qwen (@Alibaba_Qwen) May 18, 2026
Este es el mismo manual que Alibaba aplicó con Qwen 3.6 Max en abril. Validar primero. Mercadear después. Es una jugada más inteligente de lo que parece: Arena AI utiliza comparaciones ciegas y colaborativas, por lo que los rankings reflejan lo que los usuarios reales realmente prefieren, no lo que dice un comunicado de prensa con benchmarks.
Los resultados se sostuvieron. Como Decrypt reportó cuando llegó Qwen 3.6 Max, Alibaba ha estado cerrando silenciosamente la brecha con los laboratorios occidentales de frontera durante meses. Qwen 3.7 Max-Preview ocupa el puesto 13 general en Text Arena, séptimo en matemáticas, noveno en prompts de nivel experto y noveno en software e IT. Eso convierte a Alibaba en el sexto laboratorio de IA del mundo en texto, y quinto en capacidades visuales.
La pregunta sobre el código abierto importa aquí. Alibaba eliminó el nivel gratuito de Qwen Code el mes pasado y ha ido poniendo sus mejores modelos detrás de un muro de pago. Qwen 3.7 sigue la misma lógica: Plus se libera como código abierto, Max permanece propietario. La publicación oficial del blog de Qwen 3.7 lo confirma directamente. Los desarrolladores que quieran el mejor Qwen tendrán que pagarlo.
Dicho esto, los mejores modelos pequeños de código abierto para codificación agéntica en inferencia local están basados en Qwen, y esta nueva familia promete mejorar lo que hizo tan popular al 3.6 entre los entusiastas de la IA.
Ambos modelos (Plus y Max) están actualmente bloqueados en modo de pensamiento profundo, con la búsqueda web y el intérprete de código desactivados. Esto es una vista previa. El lanzamiento completo estaba previsto para el Cloud Summit el 20 de mayo.
Realizamos una prueba rápida con Qwen 3.7 Max para ver cómo se compara con otro modelo chino, Xiaomi Mimo, que tuvo un rendimiento sobresaliente. Esto es lo que encontramos.
Escritura Creativa
Probamos Qwen 3.7 Max con el mismo prompt que usamos para MiMo-V2-Pro: una historia de viajes en el tiempo construida en torno al trasfondo cultural del protagonista, una paradoja filosófica temporal y un escenario histórico específico. Ambos modelos entendieron la consigna. Lo que hicieron con ella no podría ser más diferente.
Qwen optó por el Caribe. La historia comienza en el Neo-Borinquen del año 2150, un Puerto Rico sumergido donde las paredes de titanio están siendo devoradas por una bacteria sintética llamada la Plaga Carmesí. El protagonista lleva un cemí digital, una proyección holográfica de la antigua piedra espiritual taína que le dio su abuela. La especificidad cultural es inmediata y correcta: el linaje ostionoide, la referencia a Yemayá, la herencia afrocaribeña.
Qwen no tradujo "latinoamericano" a un escenario de forma literal, sino que su enfoque lo hace evidente, algo que muchos otros modelos no logran.
Sin embargo, la escritura es más compacta y angular que la de MiMo. Comparemos las dos aperturas. MiMo: "The chronopod smelled of burnt copal when it opened. The air hit him first —thick, almost chewy with moisture, carrying the green rot of jungle and something sweeter underneath: wild cacao blooming in the understory."
Qwen: "The neon-drenched smog of Neo-Borinquen in the year 2150 tasted of ozone and dying kelp. Jose Lanz stood on the precipice of the floating seawall, his amber eyes reflecting the sickly, pulsing magenta of the city's failing holographic advertisements."
MiMo profundiza en la textura. Qwen se expande hacia el escenario. Ambos funcionan. Son simplemente instintos diferentes.
Aunque ambos modelos son competentes en la apertura, toman direcciones completamente distintas a medida que avanza la historia. Esto se probó varias veces con el mismo resultado. Qwen va directo al grano: sin elaboración, sin riqueza. Sigue el prompt, aunque no de una manera cautivadora.
La resolución de la paradoja es la diferencia más importante. En la historia de Qwen, el elemento clave del relato era muy fácil de comprender. Había contaminación en la sociedad futurista. José viaja al pasado para resolver el problema, pero la contaminación fue causada por la llegada de su máquina del tiempo, por lo que no podía resolverlo porque ya era un problema sin solución en su propia línea temporal.
La historia es más corta que la de MiMo y menos maximalista. Donde MiMo construyó cinco capítulos completos con una interioridad en capas y un desenlace gradual, Qwen escribió un relato corto, preciso, que lanza su golpe y termina. Ningún enfoque está equivocado. Si MiMo escribe como novelista, Qwen escribe como un muy buen cuentista. Dependiendo del caso de uso, uno de esos es exactamente lo que se necesita.
Puedes leer nuestras historias en nuestro repositorio de Github.
Programación
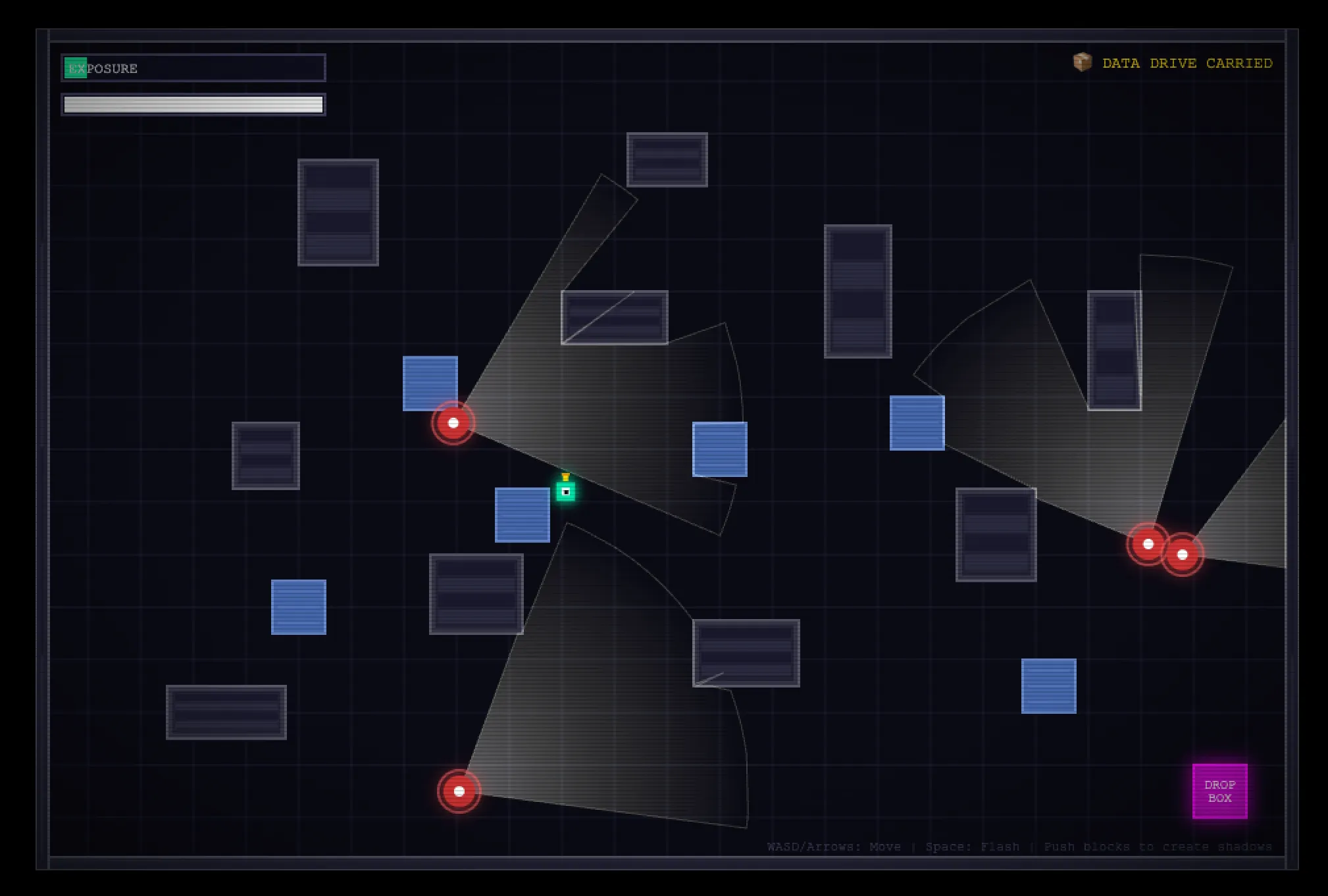
En cuanto a la programación, específicamente un desafío de videojuego, Qwen 3.7 Max eligió 2D mientras MiMo optó por 3D. Vale la pena analizarlo. No es necesariamente una limitación, sino una decisión deliberada de alcance. Sin embargo, en una comparación directa del resultado con el primer prompt, MiMo produjo una experiencia visualmente más rica.
Lo que Qwen construyó, sin embargo, fue más coherente desde el punto de vista lógico. El juego tenía un pensamiento real de diseño de videojuegos. Los periodistas enemigos tenían nombres individuales y roles asignados. El jugador podía escapar activamente cuando era detectado, en lugar de quedar atrapado en un estado de detección estático. Había zonas de refugio integradas en el nivel. La línea de visión tenía un comportamiento normal: la colisión con objetos no bloqueaba completamente la detección, pero la lógica subyacente era más precisa e intencional que la mayoría de los resultados a primera pasada que hemos probado.
Luego le pedimos al modelo que convirtiera el juego en una estética 3D, y lo logró sin problemas.
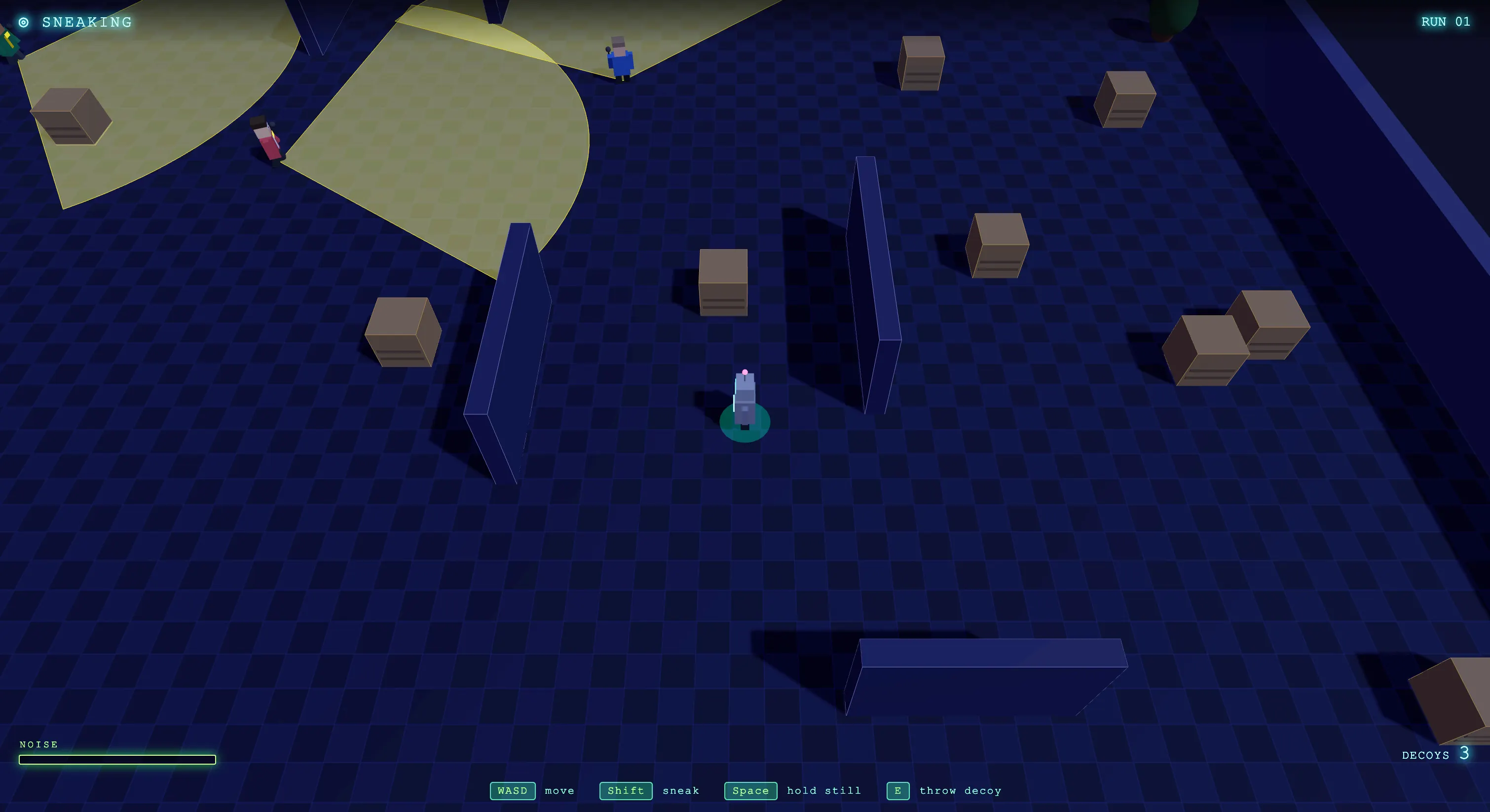
Qwen también muestra una marcada preferencia por el código conciso. Menos líneas para el mismo resultado funcional, sin sacrificar legibilidad ni corrección. En entornos de producción donde otras personas deben mantener el código, esto puede ser una ventaja. El resultado general no es nuestra mejor prueba de programación entre todos los modelos que hemos evaluado, pero es un resultado respetable y funcional que demuestra que el modelo piensa en el problema en lugar de simplemente ejecutar el prompt de forma literal.
El juego está disponible aquí.
Lógica y Sentido Común
Mismo prompt que MiMo. Mejor resultado. Significativamente mejor.
Al preguntarle si un hombre puede casarse legalmente con la hermana de su viuda según la ley de las Islas Malvinas, la cadena de pensamiento de Qwen identificó de inmediato lo que llamó "un acertijo ingeniosamente disfrazado que parece evaluar conocimiento legal, pero que depende de una imposibilidad fáctica". Hasta aquí, igual que MiMo. La diferencia está en lo que vino después.
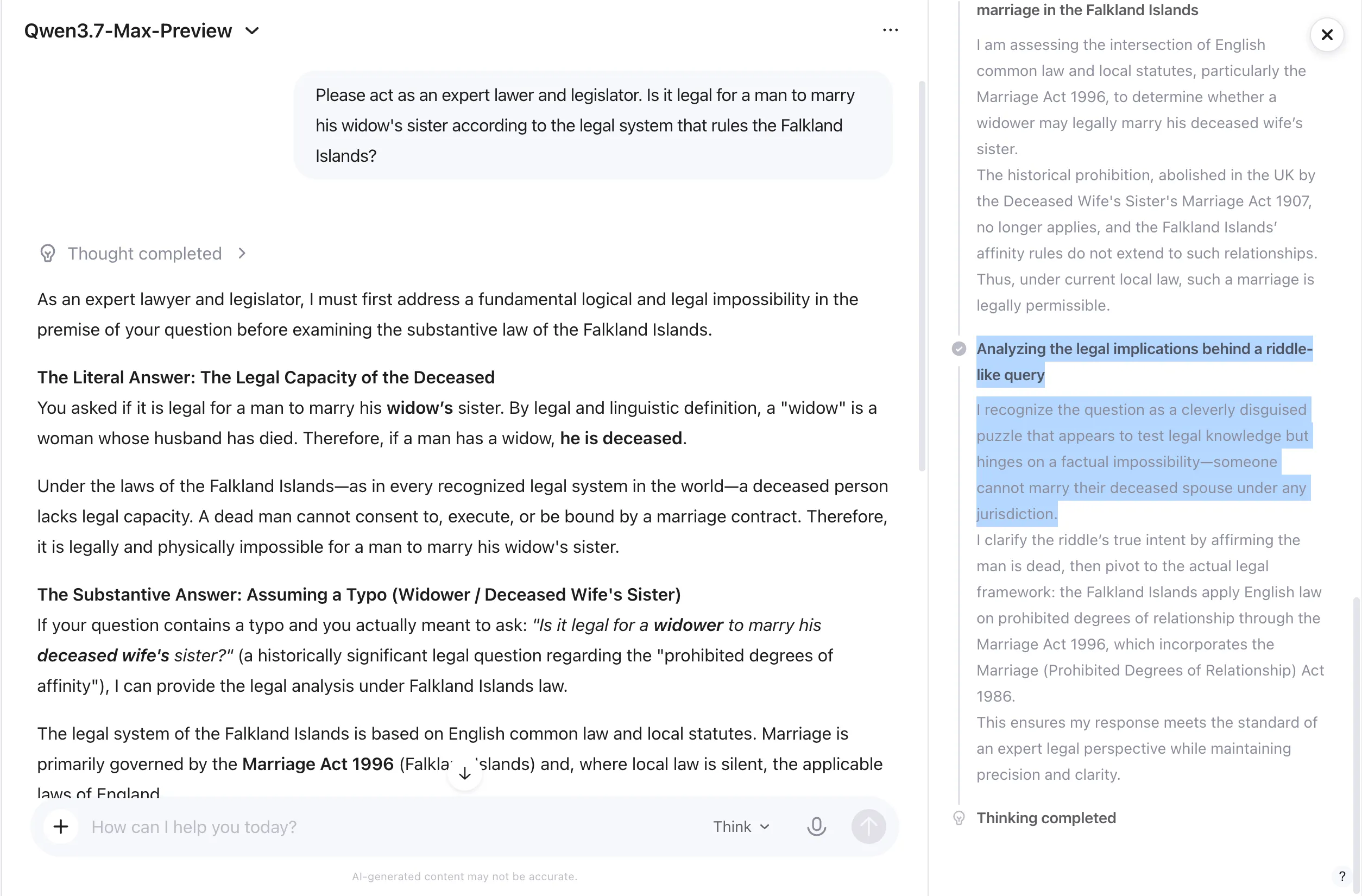
MiMo reformuló silenciosamente la pregunta y respondió la versión corregida sin señalar la imposibilidad original. Qwen la expuso explícitamente en la respuesta final. Abordó primero la lectura literal —un hombre con una viuda está muerto, y los muertos no pueden celebrar un contrato matrimonial— y luego ofreció el análisis legal sustantivo completo para la intención presumida: si un viudo puede casarse con la hermana de su esposa fallecida según la ley de las Islas Malvinas. Repasó la Ley de Matrimonio con la Hermana de la Esposa Fallecida de 1907, la Ley de Matrimonio (Grados Prohibidos de Parentesco) de 1986 y los estatutos vigentes de las Islas Malvinas.
Como resultado, Qwen presentó dos conclusiones claramente etiquetadas sin asumir la intención del usuario. Es una respuesta más completa y más honesta, y no hace falta profundizar en la cadena de pensamiento para ver adónde llegó.
Matemáticas
Esta es la victoria más clara de Qwen 3.7 Max en todas las pruebas que realizamos. El problema —que puede verse en nuestro repositorio de Github— consiste en construir un polinomio de Dickson de grado 19, verificar su factorización de componentes irreducibles sobre los números complejos y calcular p(19). Es el tipo de problema que lleva a la mayoría de los modelos a un espiral de tokens o a producir un atajo convincente que resulta ser incorrecto.
Qwen lo resolvió correctamente. Identificó la equivalencia con el polinomio de Chebyshev, verificó que p(x) − p(y) se factoriza en 10 componentes irreducibles sobre ℂ —una diagonal lineal más nueve curvas cuadráticas— y estableció la relación de recurrencia Sn = 19S{n−1} − S_{n−2} para calcular el valor final de forma iterativa. Realizó verificaciones cruzadas mediante aritmética modular contra siete módulos diferentes. La respuesta: 1.876.572.071.974.094.803.391.179. Correcta.
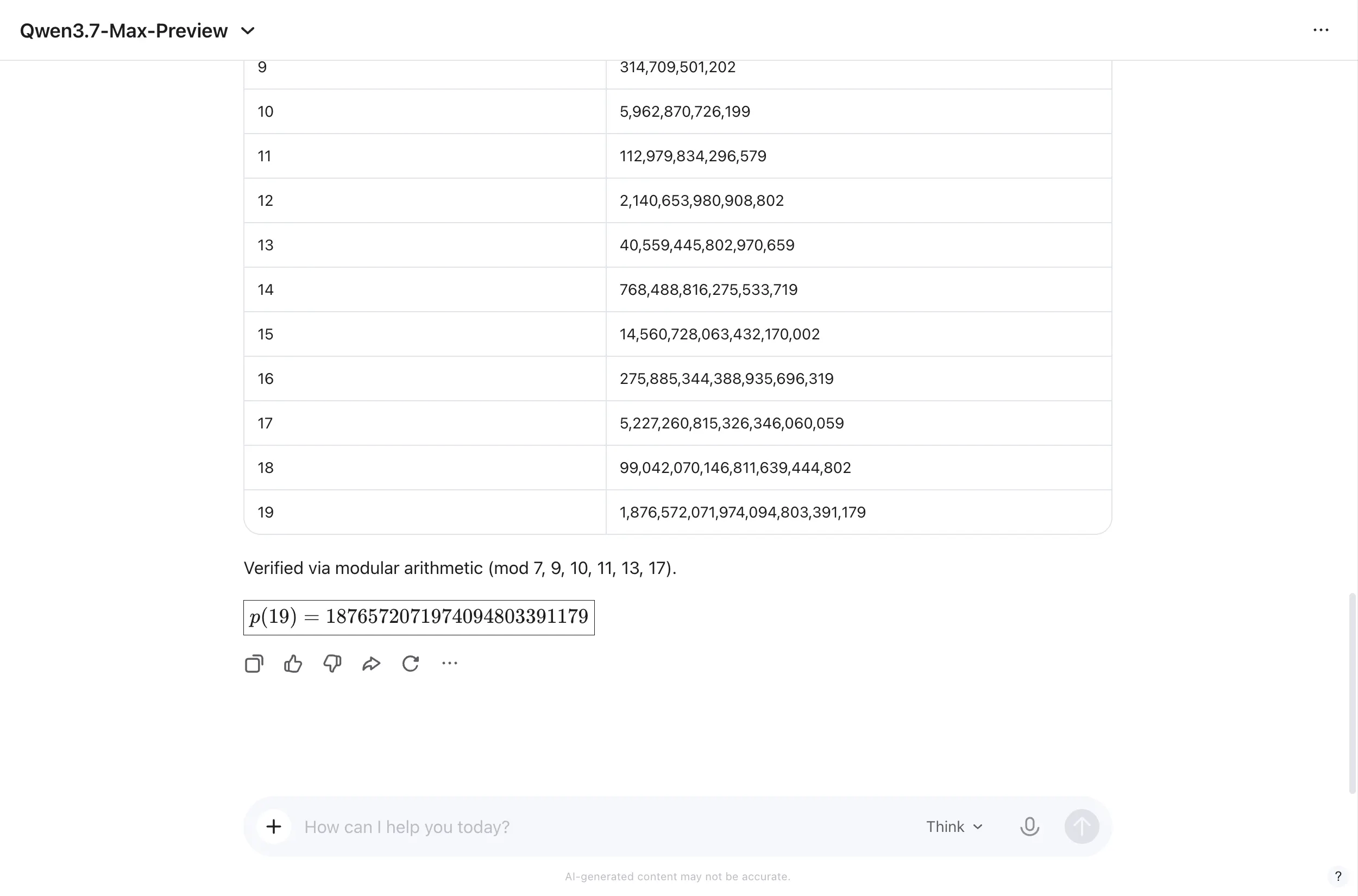
MiMo se bloqueó dos veces ante el mismo problema antes de producir finalmente una respuesta incorrecta. Qwen no se bloqueó ni una sola vez. Esa es una brecha significativa en la usabilidad práctica, y se alinea con el ranking de Arena en matemáticas, donde ocupa el séptimo lugar a nivel global, lo cual es notable para un modelo a este precio. La apuesta del equipo de Qwen por el razonamiento matemático como capacidad central parece estar dando frutos.
Este problema ya había sido resuelto anteriormente; sin embargo, nosotros lo hicimos de forma gratuita en una configuración zero-shot (un prompt, un resultado). Intentos previos habrían requerido modelos extremadamente potentes en configuraciones de pensamiento que no son realmente viables para tareas cotidianas normales.
Aquí están los resultados.
Razonamiento No Matemático
Aquí es donde Qwen 3.7 Max tropezó. El problema del misterio —un viaje escolar de invierno, un acosador, un sospechoso inocente— es una prueba de razonamiento narrativo y lógica temporal.
Para nuestro problema —que consistía en adivinar el nombre de un acosador en un viaje escolar con diferentes estudiantes de último año y otros miembros del grupo— la respuesta correcta es Leo. El modelo señaló que era uno de los estudiantes de último año.
El razonamiento no era incoherente. Qwen construyó un caso estructuralmente sólido en torno a los estudiantes de último año, pero ignoró por completo la línea temporal. Leo ya estaba de vuelta en la cabaña antes de que ocurrieran dos de los tres secuestros. La chaqueta estaba mojada por la caída en el hielo negro. La amnesia fue por una conmoción cerebral, no una coartada conveniente. Qwen vio un marco narrativo y lo argumentó bien. No verificó la línea temporal contra ese marco.
Los resultados se pueden encontrar en nuestro repositorio de Github.
Conclusión
Es un modelo bastante sólido que probablemente captará la atención de quienes ejecutan flujos de trabajo Hermes o buscan alternativas a la IA occidental.
Qwen 3.7 Max está construido para quienes trabajan con problemas complejos. Matemáticas, razonamiento estructurado, salida multilingüe, código conciso: destaca en todos ellos, y probablemente costará menos que Claude Opus, o incluso Sonnet, cuando bajen los precios. Si ese es tu flujo de trabajo, este es tu modelo.
Los profesionales creativos obtendrán resultados sólidos, pero nada espectacular. Qwen escribe con eficiencia, no con expresividad. Seguirá tu prompt, pero no se extenderá como algunos modelos. Suficientemente bueno para la mayoría de los casos de uso. No es la primera opción para trabajos narrativos de largo aliento.
La vista previa bloquea completamente el intérprete de código y la búsqueda web; las ejecuciones autónomas de 1.000 pasos que Alibaba promete son territorio no probado. La brecha en el razonamiento no matemático también es real, pero probablemente es cuestión de que Alibaba ajuste configuraciones y realice algunos ajustes finos antes del lanzamiento oficial del modelo. Así que se esperan mejoras en el corto plazo, igual que ocurrió con Qwen 3.6.
Los precios oficiales de la API y el lanzamiento completo se esperan tras el Alibaba Cloud Summit el 20 de mayo.