





OpenAI has introduced a new family of models and made them available Thursday on its paid ChatGPT Plus subscription tier, claiming that it provides major improvements in performance and reasoning capabilities.
“We are introducing OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning,” OpenAI said in an official blog post, “o1 thinks before it answers.” AI industry watchers had expected the top AI developer to deploy a new “strawberry” model for weeks, although distinctions between the different models under development are not publicly disclosed.
OpenAI describes this new family of models as a big leap forward, so much so that they changed their usual naming scheme, breaking from the ChatGPT-3, ChatGPT-3.5, and ChatGPT-4o series.
“For complex reasoning tasks, this is a significant advancement and represents a new level of AI capability,” OpenAI said. “Given this, we are resetting the counter back to one and naming this series OpenAI o1.”
Key to the operation of these new models is that they “take their time” to think before acting, the company noted, and use “chain-of-thought” reasoning to make them extremely effective at complex tasks.
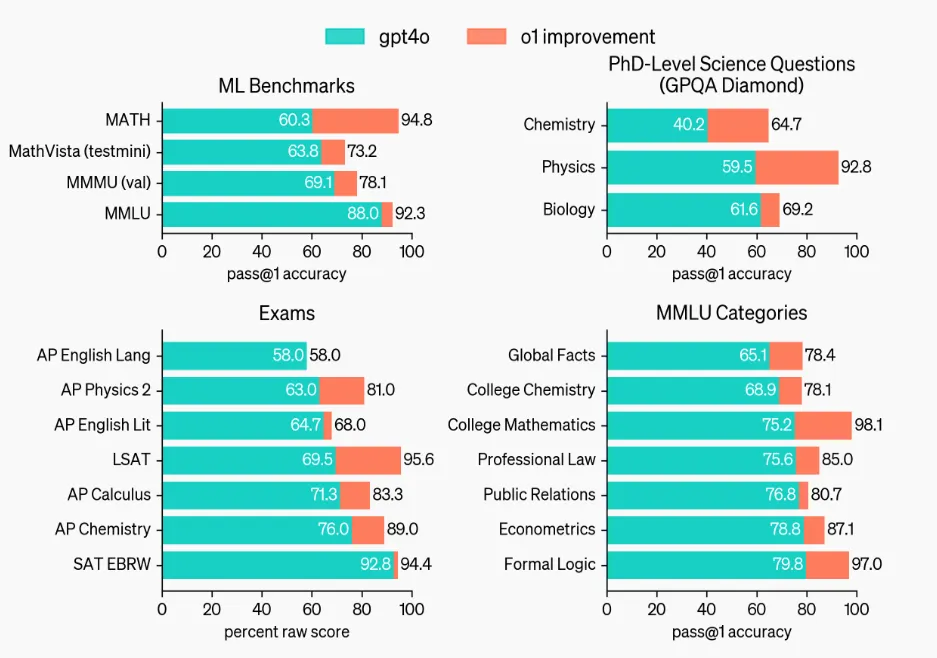
Notably, even the smallest model in this new lineup surpasses the top-tier GPT-4o in several key areas, according to AI testing benchmarks shared by Open AI—particularly OpenAI’s comparisons on challenges considered to have PhD-level complexity.
The newly released models emphasize what OpenAI calls "deliberative reasoning," where the system takes additional time to work internally through its responses. This process aims to produce more thoughtful, coherent answers, particularly in reasoning-heavy tasks.
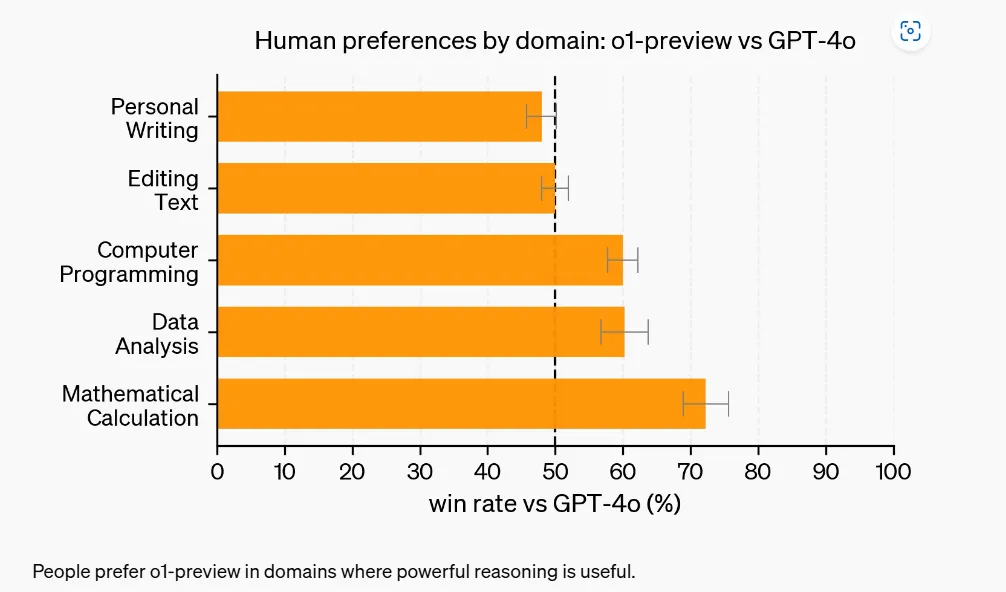
OpenAI also published internal testing results showing improvements over GPT-4o in such tasks as coding, calculus, and data analysis. However, the company disclosed that OpenAI 01 showed less drastic improvement in creative tasks like creative writing. (Our own subjective tests placed OpenAI offerings behind Claude AI in these areas.) Nonetheless, the results of its new model were rated well overall by human evaluators.
The new model's capabilities, as noted, implement the chain-of-thought AI process during inference. In short, this means the model uses a segmented approach to reason through a problem step by step before providing a final result, which is what users ultimately see.
“The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought,” OpenAI says in the o1 family’s system card. “Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits—while also increasing potential risks that stem from heightened intelligence.”
The broad assertion leaves room for debate about the true novelty of the model's architecture among technical observers. OpenAI has not clarified how the process diverges from token-based generation: is it an actual resource allocation to reasoning, or a hidden chain-of-thought command—or perhaps a mixture of both techniques?
A previous open-source AI model called Reflection had experimented with a similar reasoning-heavy approach but faced criticism for its lack of transparency. That model used tags to separate the steps of its reasoning, leading to what its developers said was an improvement over the outputs from conventional models.
I'm excited to announce Reflection 70B, the world’s top open-source model.
Trained using Reflection-Tuning, a technique developed to enable LLMs to fix their own mistakes.
405B coming next week - we expect it to be the best model in the world.
Built w/ @GlaiveAI.
Read on ⬇️: pic.twitter.com/kZPW1plJuo
— Matt Shumer (@mattshumer_) September 5, 2024
Embedding more guidelines into the chain-of-thought process not only makes the model more accurate but also less prone to jailbreaking techniques, as it has more time—and steps—to catch when a potentially harmful result is being produced.
The jailbreaking community seems to be as efficient as ever in finding ways to bypass AI safety controls, with the first successful jailbreaks of OpenAI 01 reported minutes after its release.
It remains unclear whether this deliberative reasoning approach can be effectively scaled for real-time applications requiring fast response times. OpenAI said it meanwhile intends to expand the models' capabilities, including web search functionality and improved multimodal interactions.
The model will also be tweaked over time to meet OpenAI’s minimum standards in terms of safety, jailbreak prevention, and autonomy.
The model was set to roll out today, however it may be released in phases, as some users have reported that the model is not available to them for testing yet.
The smallest version will eventually be available for free, and the API access will be 80% cheaper than OpenAI o1-preview, according to OpenAI’s announcement. But don’t get too excited: there’s currently a weekly rate of only 30 messages per week to test this new model for 01-preview and 50 for o1-mini, so pick your prompts wisely.