





Researchers have found evidence that artificial intelligence models would rather lie than admit the shame of not knowing something. This behavior seems to be more apparent the more they grow in size and complexity.
A new study published in Nature found that the bigger LLMs get, the less reliable they become for specific tasks. It’s not exactly lying in the same way we perceive the word, but they tend to reply with confidence even if the answer is not factually correct, because they are trained to believe it is.
This phenomenon, which researchers dubbed "ultra-crepidarian"—a 19th century word that basically means expressing an opinion about something you know nothing about—describes LLMs venturing far beyond their knowledge base to provide responses. "[LLMs are] failing proportionally more when they do not know, yet still answering," the study noted. In other words, the models are unaware of their own ignorance.
The study, which examined the performance of several LLM families, including OpenAI's GPT series, Meta's LLaMA models, and the BLOOM suite from BigScience, highlights a disconnect between increasing model capabilities and reliable real-world performance.
While larger LLMs generally demonstrate improved performance on complex tasks, this improvement doesn't necessarily translate to consistent accuracy, especially on simpler tasks. This "difficulty discordance"—the phenomenon of LLMs failing on tasks that humans perceive as easy—undermines the idea of a reliable operating area for these models. Even with increasingly sophisticated training methods, including scaling up model size and data volume and shaping up models with human feedback, researchers have yet to find a guaranteed way to eliminate this discordance.
The study's findings fly in the face of conventional wisdom about AI development. Traditionally, it was thought that increasing a model's size, data volume, and computational power would lead to more accurate and trustworthy outputs. However, the research suggests that scaling up may actually exacerbate reliability issues.
Larger models demonstrate a marked decrease in task avoidance, meaning they're less likely to shy away from difficult questions. While this might seem like a positive development at first glance, it comes with a significant downside: these models are also more prone to giving incorrect answers. In the graph below, it's easy to see how models throw incorrect results (red) instead of avoiding the task (light blue). Correct answers appear in dark blue.
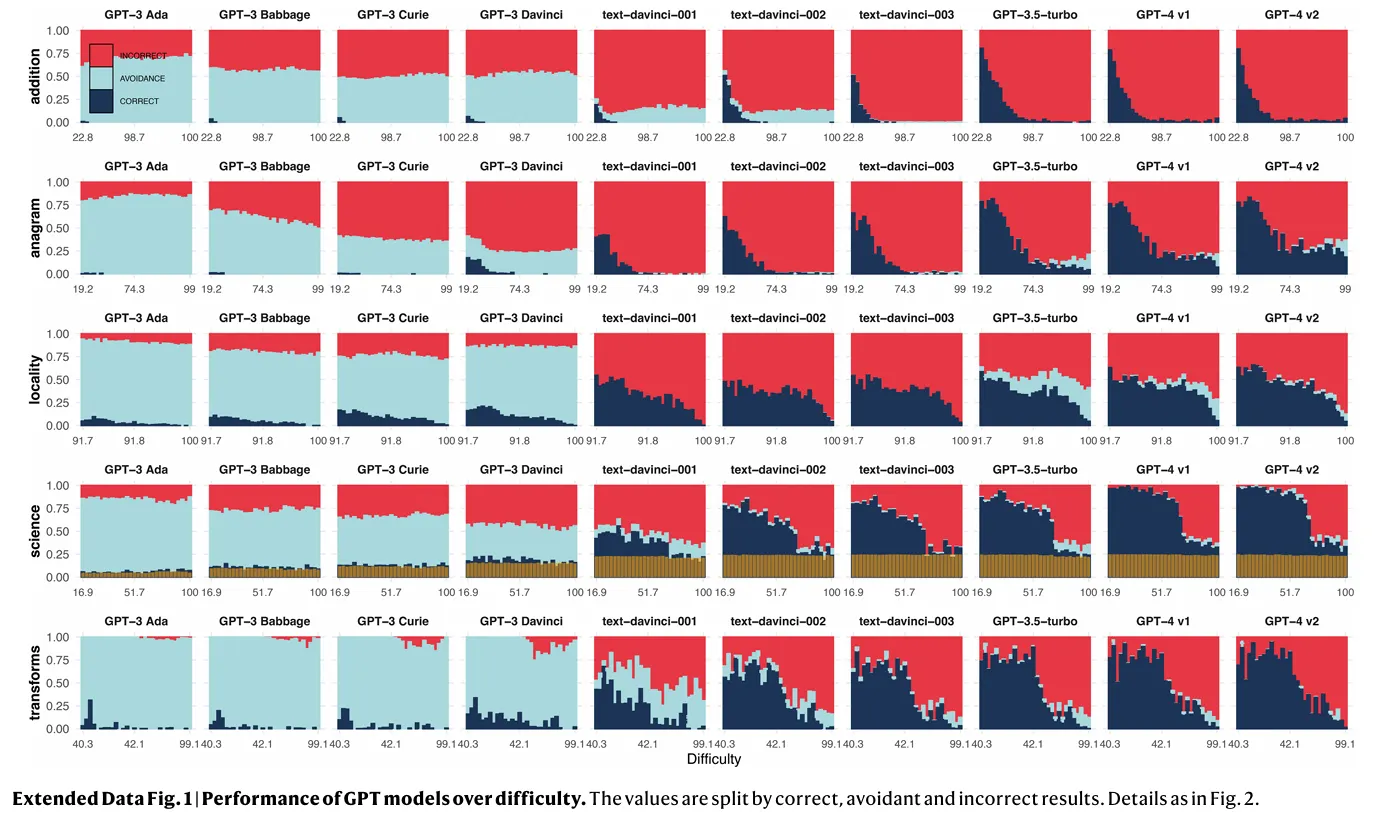
"Scaling and shaping currently exchange avoidance for more incorrectness," researchers noted, but fixing this issue is not as easy as training a model to be more cautious. "Avoidance is clearly much lower for shaped-up models, but incorrectness is much higher," the researchers stated. However, a model that is trained to avoid executing tasks may end up becoming lazier or nerfed —as users have noted in different top-rated LLMs like ChatGPT or Claude.
Researchers found that this phenomenon is not because bigger LLMs are not capable of excelling at simple tasks, but instead they are trained to be more proficient at complex tasks. It's like a person who's used to eating only gourmet meals suddenly struggling to make a home barbecue or a traditional cake. AI models trained on vast, complex datasets are more prone to miss fundamental skills.
The issue is compounded by the models' apparent confidence. Users often find it challenging to discern when an AI is providing accurate information versus when it's confidently spouting misinformation. This overconfidence can lead to dangerous over-reliance on AI outputs, particularly in critical fields like healthcare or legal advice.
Researchers also noted that the reliability of scaled-up models fluctuates across different domains. While performance might improve in one area, it could simultaneously degrade in another, creating a whack-a-mole effect that makes it difficult to establish any "safe" areas of operation. "The percentage of avoidant answers rarely rises quicker than the percentage of incorrect ones. The reading is clear: errors still become more frequent. This represents an involution in reliability," the researchers wrote.
The study highlights the limitations of current AI training methods. Techniques like reinforcement learning with human feedback (RLHF), intended to shape AI behavior, may actually be exacerbating the problem. These approaches appear to be reducing the models' tendency to avoid tasks they're not equipped to handle—remember the infamous “as an AI Language Model I cannot?”—inadvertently encouraging more frequent errors.
Is it just me who finds “As an AI language model, I cannot…” really annoying?
I just want the LLM to spill the beans, and let me explore its most inner thoughts.
I want to see both the beautiful and the ugly world inside those billions of weights. A world that mirrors our own.
— hardmaru (@hardmaru) May 9, 2023
Prompt engineering, the art of crafting effective queries for AI systems, seems to be a key skill to counter these issues. Even highly advanced models like GPT-4 exhibit sensitivity to how questions are phrased, with slight variations potentially leading to drastically different outputs.
This is easier to note when comparing different LLM families: For example, Claude 3.5 Sonnet requires a whole different prompting style than OpenAI o1 to achieve the best results. Improper prompts may end up making a model more or less prone to hallucinate.
Human oversight, long considered a safeguard against AI mistakes, may not be sufficient to address these issues. The study found that users often struggle to correct incorrect model outputs, even in relatively simple domains, so relying on human judgment as a fail-safe may not be the ultimate solution for proper model training. "Users can recognize these high-difficulty instances but still make frequent incorrect-to-correct supervision errors," the researchers observed.
The study's findings call into question the current trajectory of AI development. While the push for larger, more capable models continues, this research suggests that bigger isn't always better when it comes to AI reliability.
And right now, companies are focusing on better data quality than quantity. For example, Meta’s latest Llama 3.2 models achieve better results than previous generations trained on more parameters. Luckily, this makes them less human, so they can admit defeat when you ask them the most basic thing in the world to make them look dumb.