

In brief
- Veo 3.1 introduces full-scene audio, dialogue, and ambient sound generation.
- The launch follows Sora 2’s rapid rise to 1 million downloads within five days.
- Google positions Veo as a professional-grade alternative in the crowded AI video market.
Google released Veo 3.1 today, an updated version of its AI video generator that adds audio across all features and introduces new editing capabilities designed to give creators more control over their clips.
The announcement comes as OpenAI's competing Sora 2 app climbs app store charts and sparks debates about AI-generated content flooding social media.
The timing suggests Google wants to position Veo 3.1 as the professional alternative to Sora 2's viral social feed approach. OpenAI launched Sora 2 on September 30 with a TikTok-style interface that prioritizes sharing and remixing.
The app hit 1 million downloads within five days and reached the top spot in Apple's App Store. Meta took a similar approach, with its own sort of virtual social media powered by AI videos.
Users can now create videos with synchronized ambient noise, dialogue, and Foley effects using "Ingredients to Video," a tool that combines multiple reference images into a single scene.
The "Frames to Video" feature generates transitions between a starting and ending image, while "Extend" creates clips lasting up to a minute by continuing the motion from the final second of an existing video.
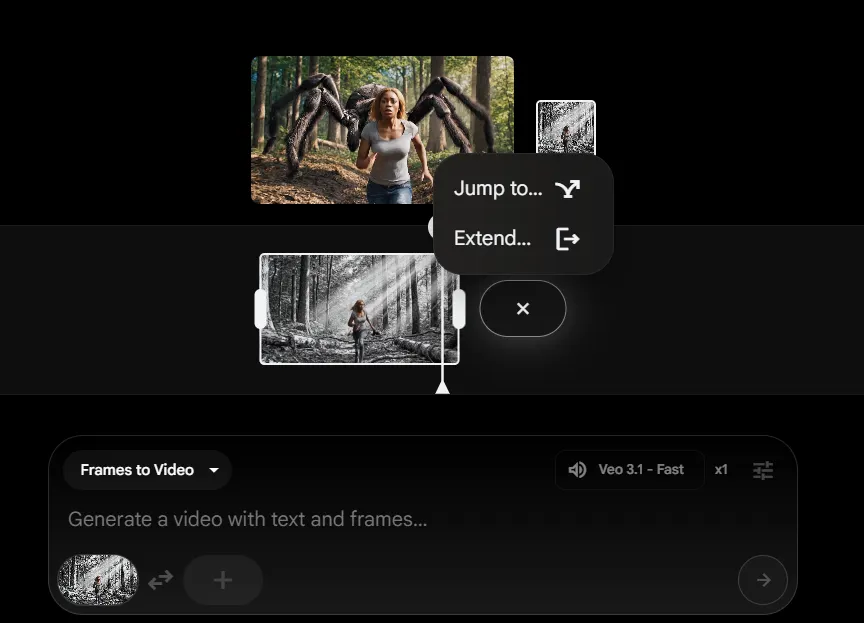
New editing tools let users add or remove elements from generated scenes with automatic shadow and lighting adjustments. The model generates videos in 1080p resolution at horizontal or vertical aspect ratios.
The model is available through Flow for consumer use, the Gemini API for developers, and Vertex AI for enterprise customers. Videos lasting up to a minute can be created using the "Extend" feature, which continues motion from the final second of an existing clip.
The AI video generation market has become crowded in 2025, with Runway's Gen-4 model targeting filmmakers, Luma Labs offering fast generation for social media, Adobe integrating Firefly Video into Creative Cloud, and updates from xAI, Kling, Meta, and Google targeting realism, sound generation, and prompt adherence.
But how good is it? We tested the model, and these are our impressions.
Testing the model
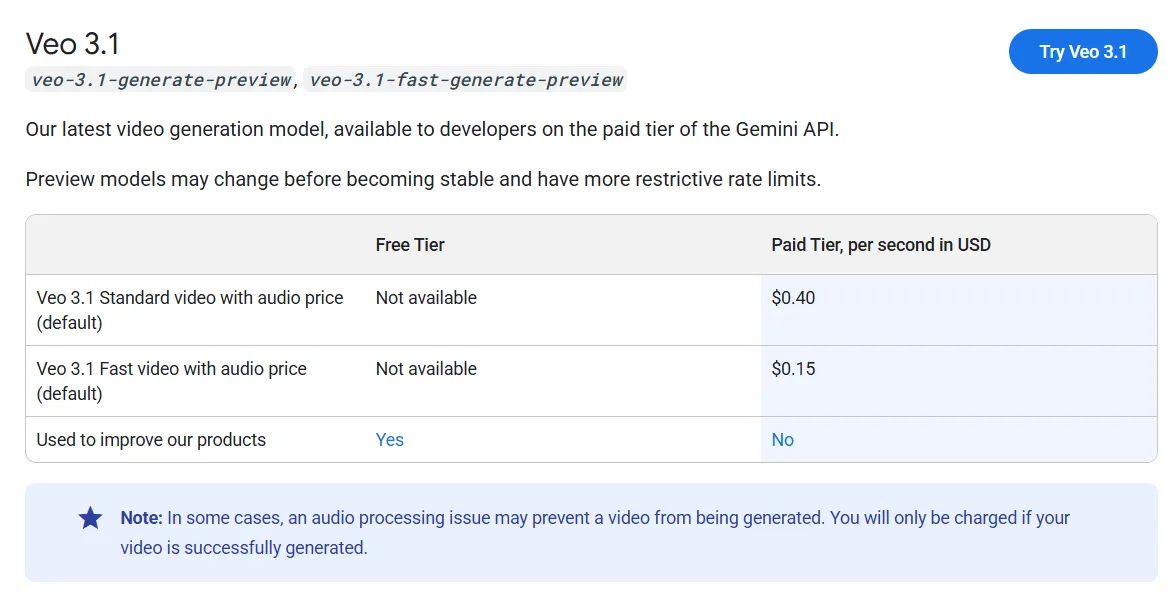
If you want to try it, you'd better have some deep pockets. Veo 3.1 is currently the most expensive video generation model, on par with Sora 2 and only behind Sora 2 Pro, which costs more than twice as much per generation.
Free users receive 100 monthly credits to test the system, which is enough to generate around five videos per month. Through the Gemini API, Veo 3.1 costs approximately $0.40 per second of generated video with audio, while a faster variant called Veo 3.1 Fast costs $0.15 per second.
For those willing to use it at that price, here are its strengths and weaknesses.
Text to Video
Veo 3.1 is a definite improvement over its predecessor. The model handles coherence well and demonstrates a better understanding of contextual environments.
It works across different styles, from photorealism to stylized content.
We asked the model to blend a scene that started as a drawing and transitioned into live-action footage. It handled the task better than any other model we tested.
Without any reference frame, Veo 3.1 produced better results in text-to-video mode than it did using the same prompt with an initial image, which was surprising.
The tradeoff is movement speed. Veo 3.1 prioritizes coherence over fluidity, making it challenging to generate fast-paced action.
Elements move more slowly but maintain consistency throughout the clip. Kling still leads in rapid movement, although it requires more attempts to achieve usable results.
Image to Video
Veo built its reputation on image-to-video generation, and the results still deliver—with caveats. This appears to be a weaker area in the update. When using different aspect ratios as starting frames, the model struggled to maintain the coherence levels it once had.
If the prompt strays too far from what would logically follow the input image, Veo 3.1 finds a way to cheat. It generates incoherent scenes or clips that jump between locations, setups, or entirely different elements.
This wastes time and credits, since these clips can't be edited into longer sequences because they don't match the format.
When it works, the results look fantastic. Getting there is part skill, part luck—mostly luck.
Elements to Video
This feature works like inpainting for video, letting users insert or delete elements from a scene. Don't expect it to maintain perfect coherence or use your exact reference images, though.
For example, the video below was generated using these three references and the prompt: a man and a woman stumble upon each other while running in a futuristic city, where a Bitcoin sign hologram is rotating. The man tells the woman, "QUICK, BITCOIN CRASHED! WE MUST BUY MORE!!

As you can see, neither the city nor the characters are actually there. However, characters are wearing the clothes of reference, the city resembles the one in the in the image, and things portray the idea of the elements, not the elements themselves.
Veo 3.1 treats uploaded elements as inspiration rather than strict templates. It generates scenes that follow the prompt and include objects that resemble what you provided, but don't waste time trying to insert yourself into a movie—it won't work.
A workaround: use Nanobanana or Seedream to upload elements and generate a coherent starting frame first. Then feed that image to Veo 3.1, which will produce a video where characters and objects show minimal deformation throughout the scene.
Text to Video with Dialogue
This is Google's selling point. Veo 3.1 handles lip sync better than any other model currently available. In text-to-video mode, it generates coherent ambient sound that matches scene elements.
The dialogue, intonation, voices, and emotions are accurate and beat competing models.
Other generators can produce ambient noise, but only Sora, Veo, and Grok can generate actual words.
Of those three, Veo 3.1 requires the fewest attempts to get good results in text-to-video mode.
Image to Video with Dialogue
This is where things fall apart. Image-to-video with dialogue suffers from the same issues as standard image-to-video generation. Veo 3.1 prioritizes coherence so heavily that it ignores prompt adherence and reference images.
For example, this scene was generated using the reference shown in the elements to video section.
As you can see, our test generated a completely different subject than the reference image. The video quality was excellent—intonation and gestures were spot-on—but it wasn't the person we uploaded, making the result useless.
Sora's remix feature is the best choice for this use case. The model may be censored, but its image-to-video capabilities, realistic lip sync, and focus on tone, accent, emotion, and realism make it the clear winner.
Grok's video generator comes in second. It respected the reference image better than Veo 3.1 and produced superior results. Here is one generation using the same reference image and prompt.
If you don't want to deal with Sora's social app or lack access to it, Grok might be your best option. It's also uncensored but moderated, so if you need that particular approach, Musk has you covered.