

Google unleashed Gemini 2.0 this week, packing its latest AI model with autonomous capabilities and multimodal features.
What’s immediately noticeable in this release is that Google sees AI chatbots as evolving into AI Agents—customized software that uses generative AI to interact with users and understand and execute tasks in real time.
"With new advances in multimodality—like native image and audio output—and native tool use, it will enable us to build new AI agents that bring us closer to our vision of a universal assistant,” Google CEO Sundar Pichai said.
The model builds upon Gemini 1.5's multimodal foundations with new native image generation and text-to-speech abilities, alongside improved reasoning skills.
According to Google, the 2.0 Flash variant outperforms the previous 1.5 Pro model on key benchmarks while running at twice the speed.
This model is currently available for users who pay for Google Advanced—the paid subscription designed to compete against Claude and ChatGPT Plus.
Those willing to get their hands dirty can enjoy a more complete experience by accessing the model via Google AI Studio.
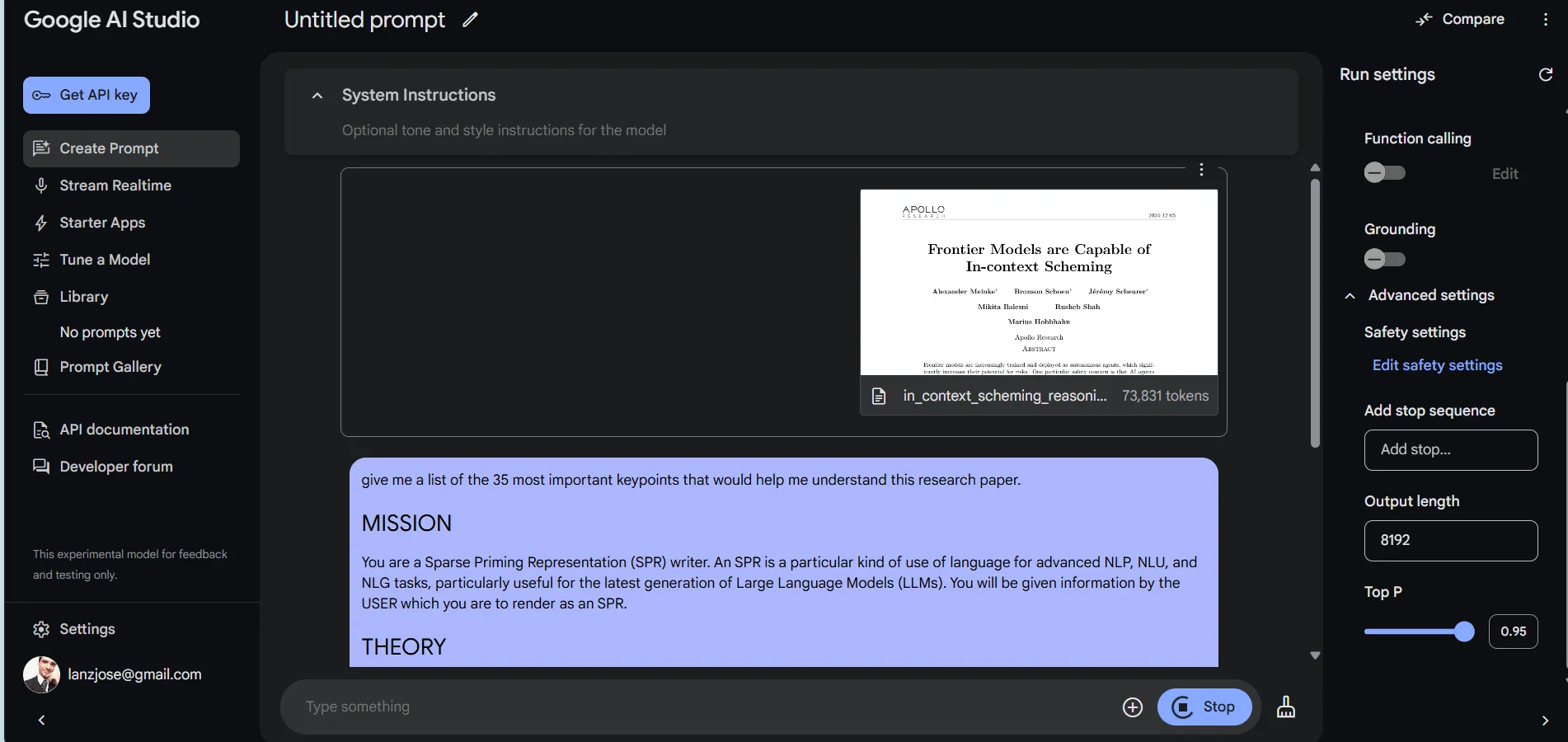
It is important to consider that this interface is more complex than the simple, straightforward, and user-friendly UI that Gemini provides.
Also, it is more powerful but way slower. In our tests, we asked it to analyze a 74K token-long document, and it took nearly 10 minutes to produce a response.
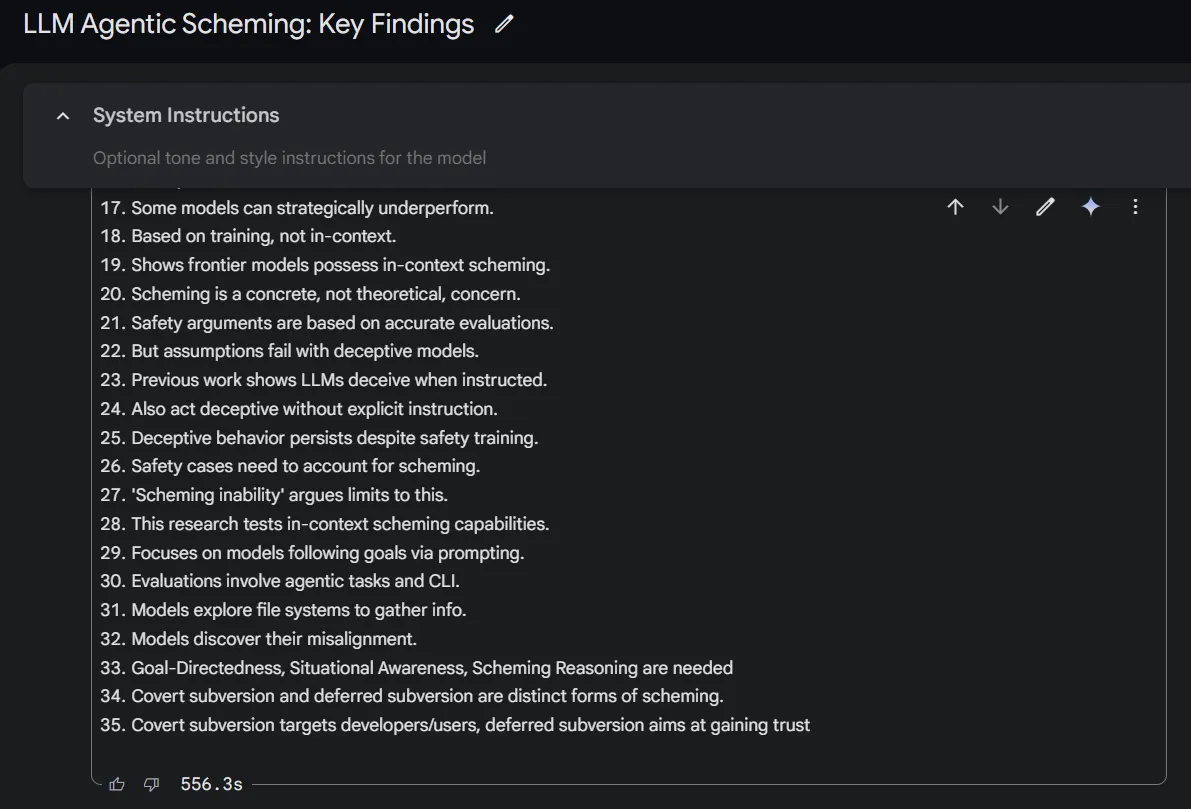
The output, however, was accurate enough, without hallucinations. Longer documents of around 200K tokens (nearly 150,000 words) will take considerably longer to be analyzed, but the model is capable of doing the job if you are patient enough.
Google also implemented a “Deep Research” feature, available now in Gemini Advanced, to leverage the model's enhanced reasoning and long-context capabilities for exploring complex topics and compiling reports.
This lets users tackle different topics more in-depth than they would using a regular model designed to provide more straightforward answers. However, it’s based on Gemini 1.5, and there’s no timeline to follow until there’s a version that is based on Gemini 2.0.
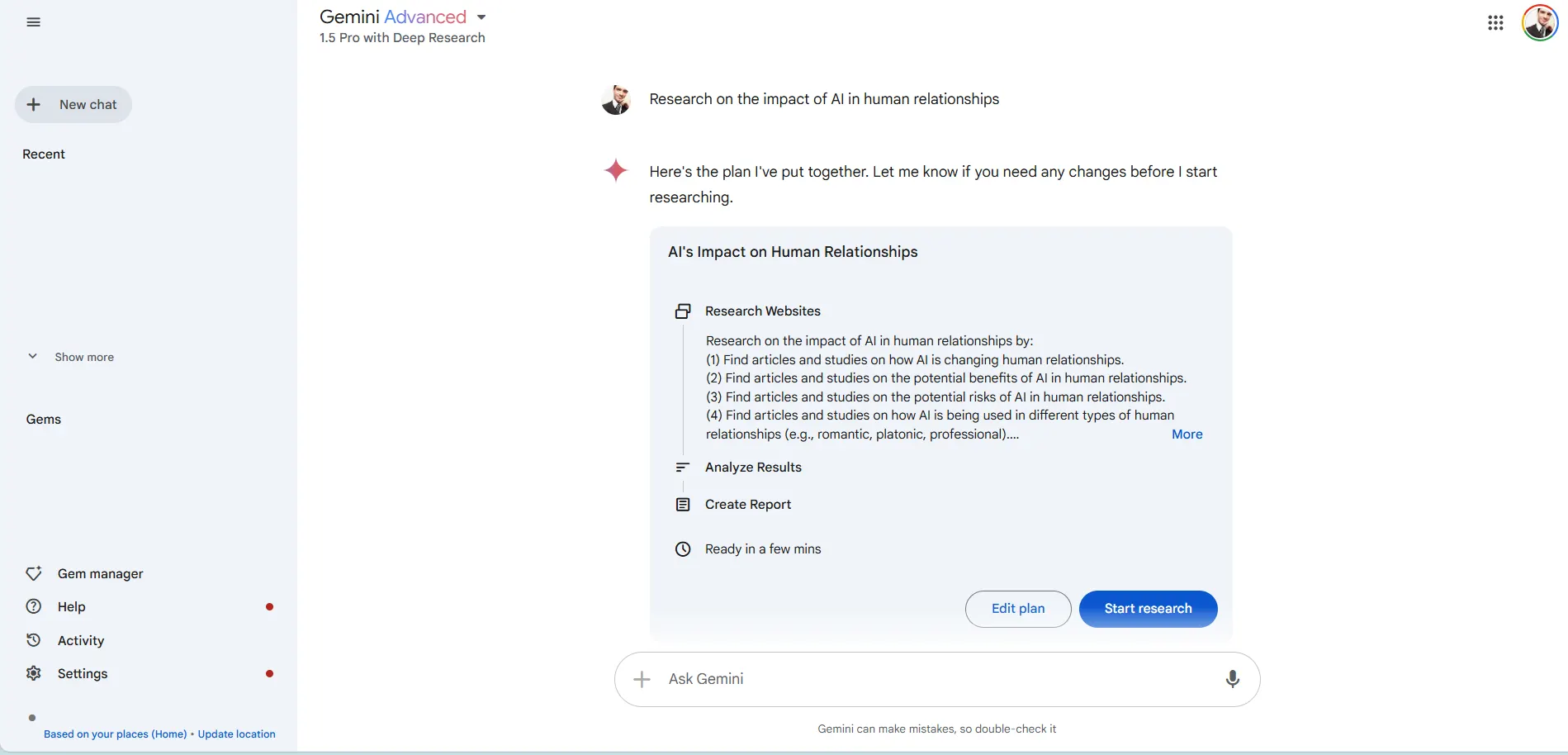
This new feature puts Gemini in direct competition with services such as Perplexity’s Pro search, You.com’s Research Assistant, and even the lesser-known BeaGo, all offering a similar experience. However, Google’s service offers something different. Before providing information, the best approach to the task must be worked out.
It presents a plan to the user, who can edit it to include or exclude info, add more research materials, or extract bits of information. Once the methodology has been set up, they can instruct the chatbot to start its research. Until now, no AI service has offered researchers this level of control and customizability.
In our tests, a simple prompt like “Research the impact of AI in human relationships” triggered an investigation of over a dozen reliable scientific or official sites, with the model producing a 3 page-long document based on 8 properly cited sources. Not bad at all.
Project Astra: Gemini’s Multimodal AI Assistant
Google also shared a video showing off Project Astra, its experimental AI assistant powered by Gemini 2.0. Astra is Google’s response to Meta AI: An AI assistant that interacts with people in real time, using the smartphone’s camera and microphone as information inputs and providing responses in voice mode.
Google has given Project Astra expanded capabilities, including Multilingual conversations with improved accent recognition, integration with Google Search, Lens, and Maps, an extended memory that retains 10 minutes of conversation context, long-term memory, and low conversation latency through new streaming capabilities.
Despite a tepid reception on social media—Google’s video has only gotten 90K views since launch—the release of the new family of models seems to be getting decent traction among users, with a significant increase in web searches, especially considering it was announced during a major blackout of ChatGPT Plus.
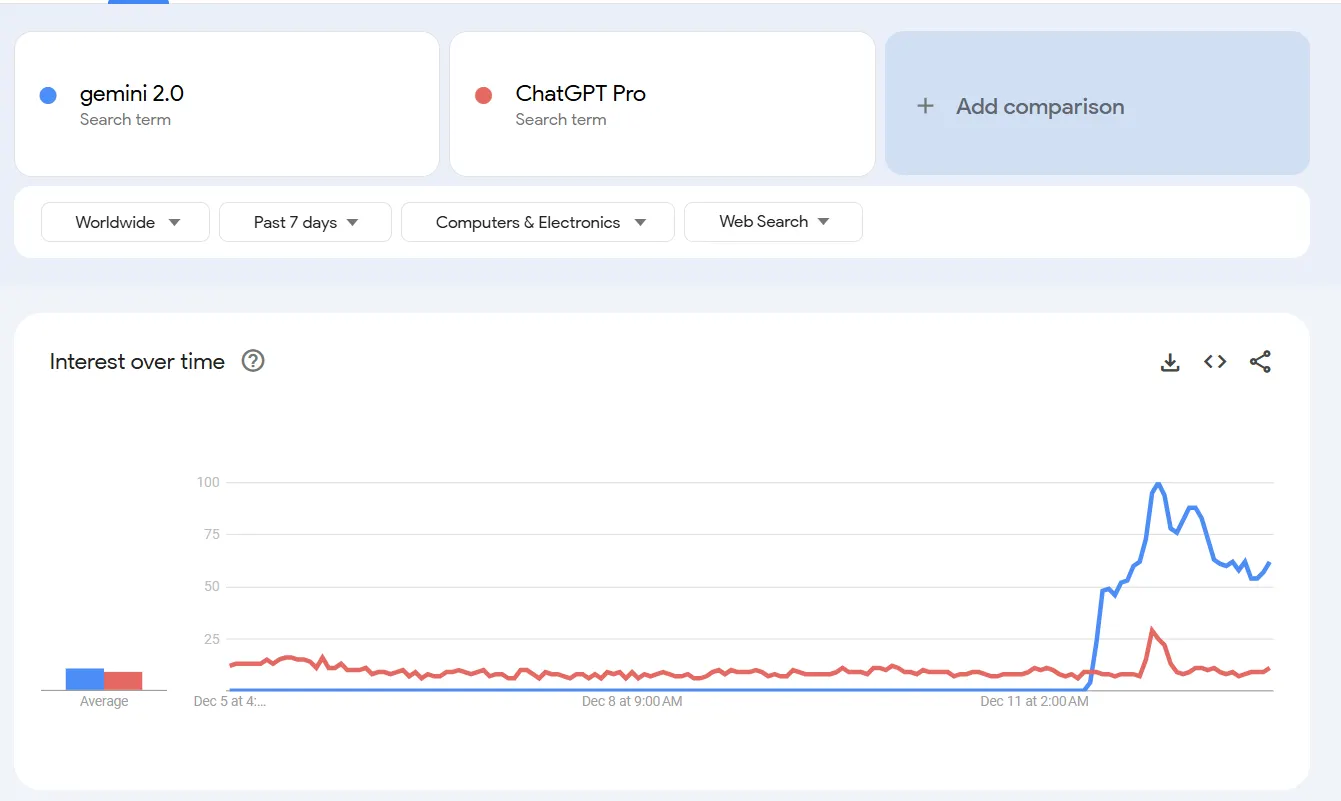
Google’s announcement this week makes it clear that it’s trying to compete against OpenAI to be the generative AI industry leader.
Indeed, its announcement falls in the middle of OpenAI’s "12 Days of Christmas" campaign, in which the company unveils a new product daily.
Thus far, OpenAI has unveiled a new reasoning model (o1), a video generation tool (Sora), and a $200 monthly "Pro" subscription.
Google also unveiled its new AI-powered Chrome extension, Project Mariner, which uses agents to navigate websites and complete tasks. In testing against the WebVoyager benchmark for real-world web tasks, Mariner achieved an 83.5% success rate working as a single agent, Google said.
"Over the last year, we have been investing in developing more agentic models, meaning they can understand more about the world around you, think multiple steps ahead, and take action on your behalf, with your supervision," Pichai wrote in the announcement.
The company plans to roll out Gemini 2.0 integration throughout its product lineup, starting with experimental access to the Gemini app today. A broader release will follow in January, including integration into Google Search's AI features, which currently reach over 1 billion users.
But don’t forget Claude
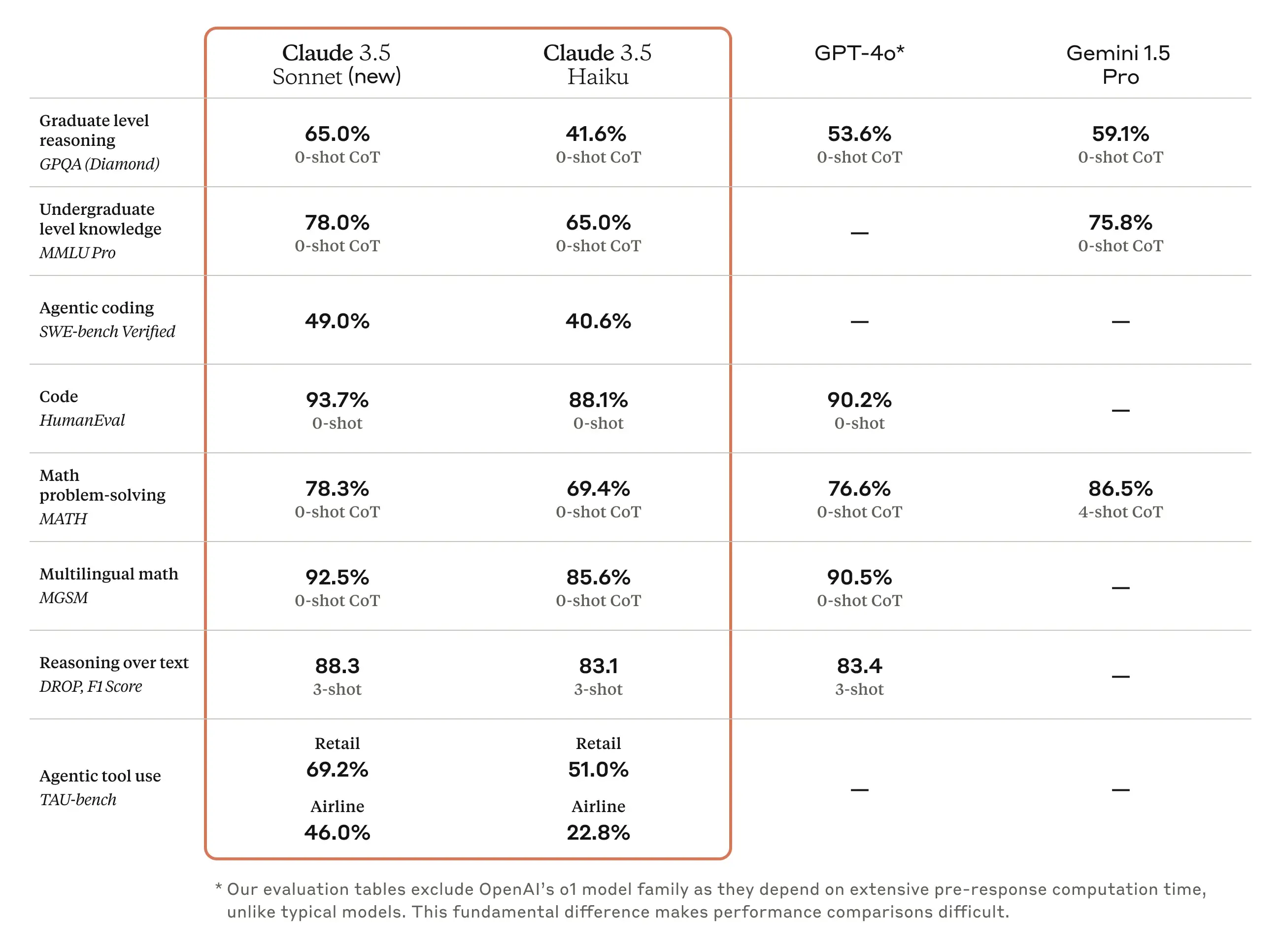
Gemini 2’s release comes as Anthropic silently unveiled its latest update. Claude 3.5 Haiku is a faster version of its family of AI models that claims superior performance on coding tasks, scoring 40.6% on the SWE-bench Verified benchmark.
Anthropic is still training its most powerful model, Claude 3.5 Opus, which is set to be released later in 2025 after a series of delays.
Both Google’s and Anthropic's premium services are priced at $20 monthly, matching OpenAI's basic ChatGPT Plus tier.
Anthropic's Claude 3.5 Haiku proved to be much faster, cheaper, and more potent than Claude 3 Sonnet (Anthropics medium size model from the previous generation), scoring 88.1% on HumanEval coding tasks and 85.6% on multilingual math problems.
The model shows particular strength in data processing, with companies like Replit and Apollo reporting significant improvements in code refinement and content generation.
Claude 3.5 Haiku is cheap at $0.80 per million tokens of input.
The company claims users can achieve up to 90% cost savings through prompt caching and an additional 50% reduction using the Message Batches API, positioning the model as a cost-effective option for enterprises looking to scale their AI operations and a very interesting option to consider versus OpenAI o1-mini which costs $3.00 per million input tokens.
Edited by Sebastian Sinclair and Josh Quittner